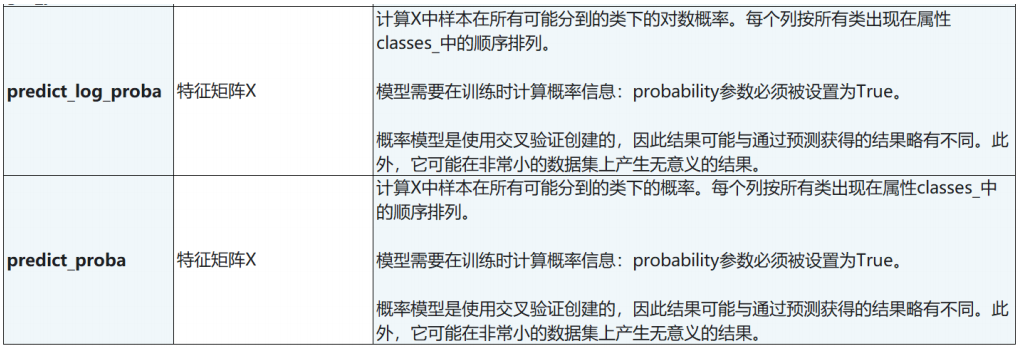
API
化学信息学
nosql
汇编
nlp
安全威胁分析
rpc
网络攻击模型
.net
心理健康管理系统
File的构造方法
堆排序
格式
图搜索算法
PMP项目管理
MVCC
防火墙
考博
TF-A
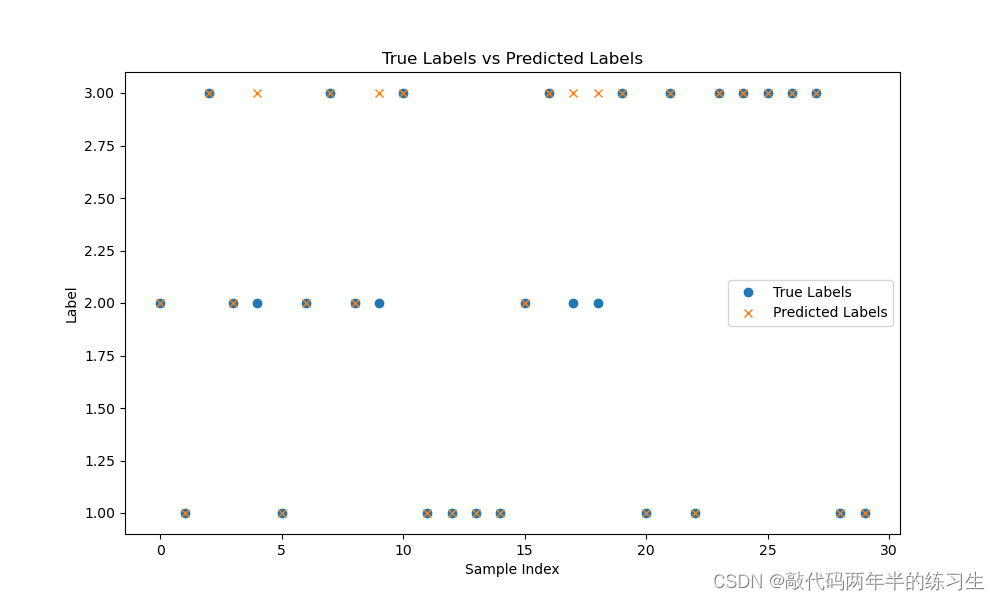
华为上机考试真题
sklearn
2024/4/11 15:44:37
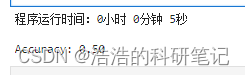
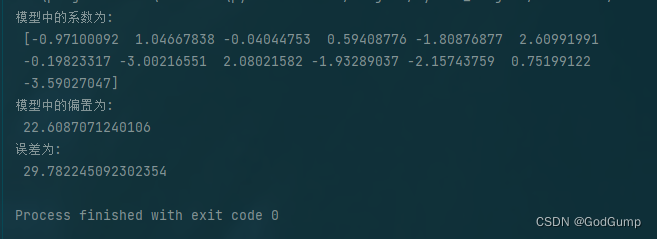
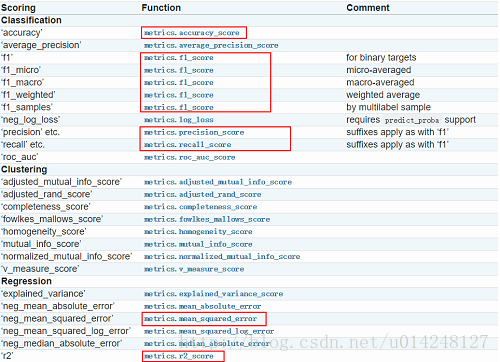
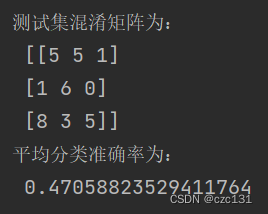
sklearn包中对于分类问题,如何计算accuracy和roc_auc_score?
1. 基础条件
import numpy as np
from sklearn import metricsy_true np.array([1, 7, 4, 6, 3])
y_prediction np.array([3, 7, 4, 6, 3])2. accuracy_score计算
acc metrics.accuracy_score(y_true, y_prediction)这个没问题
3. roc_auc_score计算
The binary and mul…
5、【Grid_Search-K折合交叉验证】使用网格搜索进行k折合交叉验证寻找最佳算法参数组合
上次案例中,通过手动写K折合交叉验证找出了最佳参数,然而在最终预测结果上并不理想,故此处使用sklearn自带的Grid_Search(网格搜索)库进行搜索。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
X_under_train,…
2、【数据特征预处理】(接上一章特征抽取即转文本数据为数值数据后,特征的标准化、缺失值处理以及特征值选择)
所谓数据特征预处理即是在将文本数据转换为数值数据之后的进一步操作,归一化/标准化以及缺失值处理、特征选择。sklearn. preprocessing最小最大归一化: 归一化步骤: 1、实例化MinMaxScalar2、通过fit_transform转换sklearn.preprocessing.MinMaxScaler
MinMaxScalar(featur…
Python 机器学习,数据的标准化
数据的标准化方式
有两种常见的方法可以让所有的属性有相同的量度:线性函数归一化(Min-Max scaling)和标准化(standardization)。
方式 1:StandardScaler()
from sklearn.preprocessing import Standard…
数模竞赛代码整理----分类器
文章目录数据准备数据不均衡问题SMOTE过采样EasyEnsembleClassifier具体的分类器分类器的实现较为简单,主要从sklearn库中调取需要的函数即可。sklearn yyds!!!数据准备
数据不均衡问题
比如说本题,分类为0的样本有4…
【sklearn练习】鸢尾花
一、
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
第二行:导入datasets数据集
第三行:train_test_split 的作用是将数据集随机分配…
聚类笔记/sklearn笔记:Affinity Propagation亲和力传播
1 算法原理
1.1 基本思想
将全部数据点都当作潜在的聚类中心(称之为 exemplar )然后数据点两两之间连线构成一个网络( 相似度矩阵 )再通过网络中各条边的消息( responsibility 和 availability )传递计算出各样本的聚类中心。 1.2 主要概念
Examplar聚类中心similarity S(i…
机器学习之多层感知机原理详解、公式推导(手推)、面试问题、简单实例(python实现,sklearn调包)
目录1. 多层感知机原理神经元概念误差反向传播更新权重2. 公式推导3. 实例3.1. 数据集3.2. python3.3. torch4. 几个注意点(面试问题)5. 运行(可直接食用)1. 多层感知机原理
神经元概念 多层感知机就是由好几层神经元组成的,每个神经元包括输…
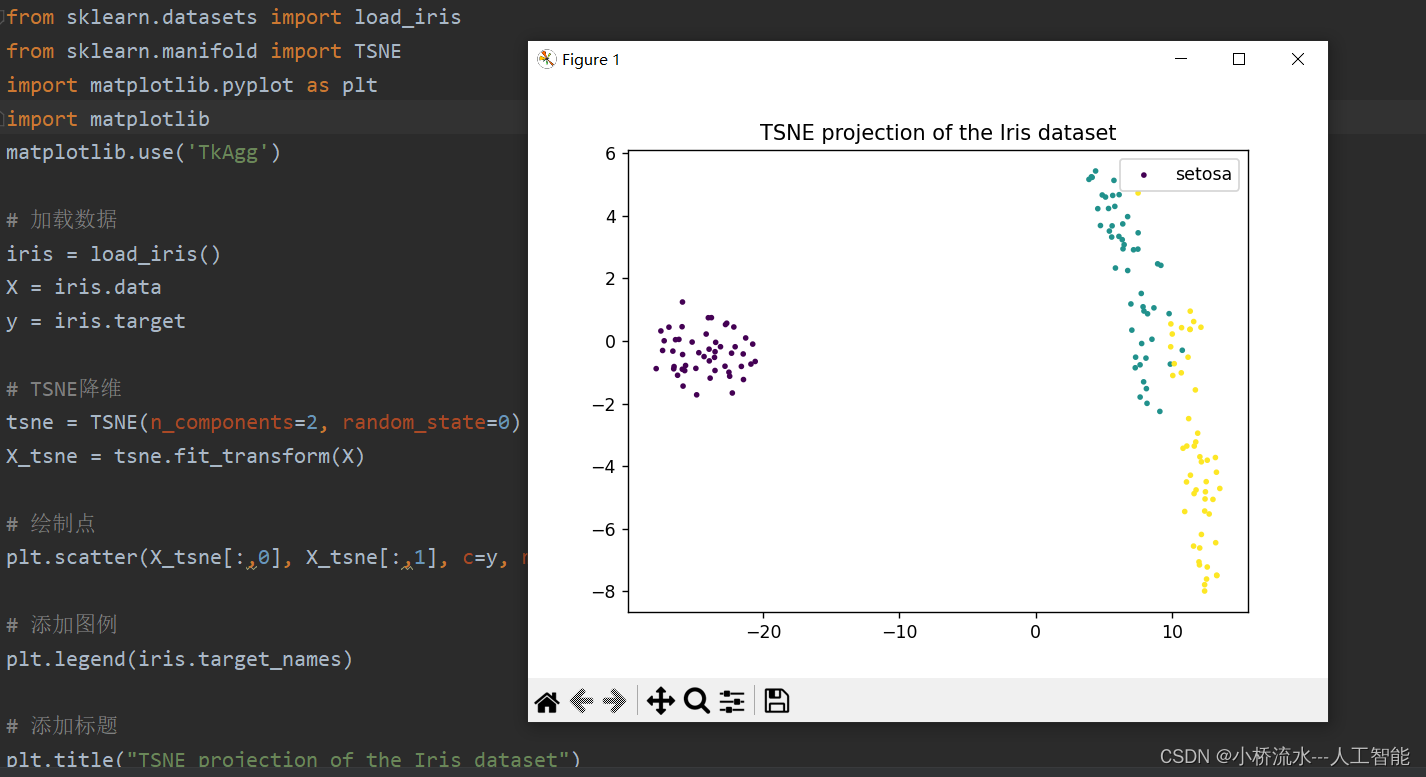
详细解答T-SNE程序中from sklearn.manifold import TSNE的数据设置,包括输入数据,绘制颜色的参数设置,代码复制可用!!
文章目录 前言——TSNE是t-Distributed Stochastic Neighbor Embedding的缩写1、可运行的T-SNE程序2. 实验结果3、针对上述程序我们详细分析T-SNE的使用方法3.1 加载数据3.2 TSNE降维3.3 绘制点3.4 关于颜色设置,颜色使用的标签数据的说明cy 总结 前言——TSNE是t-D…
sklearn 中matplotlib编制图表
代码
# 导入pandas库,并为其设置别名pd
import pandas as pd
import matplotlib.pyplot as plt# 使用pandas的read_csv函数读取名为iris.csv的文件,将数据存储在iris_data变量中
iris_data pd.read_csv(data/iris.txt,sep\t)# 使用groupby方法按照&quo…

机器学习——模型保存、模型加载
# coding:utf-8 # 1.获取数据集 #2.数据基本处理 #2.1.数据划分 #3.特征工程——标准化 #4.机器学习(线性回归) #5.模型评估 from sklearn.datasets import load_boston # 1.获取数据集,所使用的引用 from sklearn.model_selection import train_test_sp…
【Sklearn】基于多层感知器算法的数据分类预测(Excel可直接替换数据)
【Sklearn】基于多层感知器算法的数据分类预测(Excel可直接替换数据) 1.模型原理2.模型参数3.文件结构4.Excel数据5.下载地址6.完整代码7.运行结果1.模型原理
多层感知器(Multilayer Perceptron,MLP)是一种前馈神经网络,用于解决分类和回归问题。它包含输入层、若干个隐…
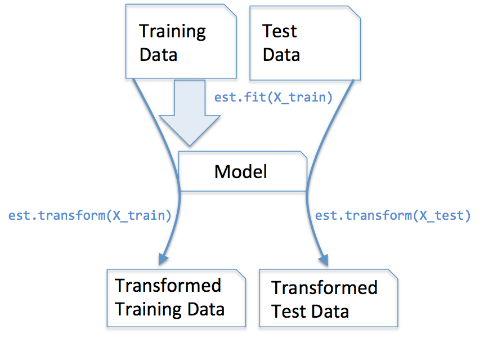
sklearn模块中fit_transform()函数和transform()函数之间的区别
一.先说结论1. fit_transform()的作用就是先拟合数据,然后转化它将其转化为标准形式,一般应用在训练集中。2. tranform()的作用是通过找中心和缩放等实现标准化,一般用在测试集中。二. 问题背景对于数据预处理中涉及到的fit_transform()函数和…

机器学习-鸢尾花【K近邻算法(knn)带【交叉验证】适合于大样本的自动分类
Created on 2022年1月16日 1.获取数据集 2.数据基本处理 3.特征工程 4.机器学习(模型训练) 5.模型评估 author: datangzn from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler f…
【Python机器学习】sklearn.datasets样本生成操作
如何在没有真实数据的情况下,依然能够测试和优化机器学习模型?
在机器学习的实验或研究中,有时候手头并没有合适的数据集进行模型训练和测试。这时候合成或模拟数据集就显得尤为重要。sklearn.datasets模块就是这样一个强大的工具,它提供了一系列函数,不仅可以用于生成各…
sklearn 笔记: neighbors.BallTree
球树结构
1 基本使用方法
sklearn.neighbors.BallTree(X, leaf_size40, metricminkowski, **kwargs)
2 主要参数说明
X 输入数据,维度为 (n_samples, n_features) n_samples 是数据集中点的数量n_features 是参数空间的维数leaf_size 点数少于多少时,…
scikit-learn : 岭回归
背景
岭回归可以弥补线性回归的不足,它引入了正则化参数来”缩减”相关系数,可以理解为对相关系数做选择。当数据集中存在共线性的时候,岭回归就会有用。
让我们加载一个不满秩(low effective rank)数据集来比较岭回…

sklearn中的支持向量机SVM(下)
1 二分类SVC的进阶
1.1 SVC用于二分类的原理复习
sklearn中的支持向量机SVM(上)
1.2 参数C的理解进阶
有一些数据,可能是线性可分的,但在线性可分状况下训练准确率不能达到100%,即无法让训练误差为0。这种数据被称…
scikit-learn中离散特征二值化
scikit-learn中离散特征二值化 最近在看西瓜书用scikit-learn中的CART去跑西瓜数据集,结果遇到麻烦了,西瓜数据集特征不光离散的,而且还是中文的。。(PS:其实我们的数据集中特征值常常是离散的类别,这个很正…

scikit learn Splitter Classes:KFold、GroupFold、StratifiedKFold及变体
创建于:20220105 修改于:20220106 文章目录1、Splitter Classes概述2、KFold2.1 方法介绍2.2 参数介绍2.3 图形化解说2.4 代码样例3、GroupKFold3.1 方法介绍3.2 参数介绍3.3 图形化解说3.4 代码样例4、StratifiedKFold4.1 方法介绍4.2 参数介绍4.3 图形…
(7) 支持向量机(上)
文章目录 1 概述1.1 支持向量机分类器是如何工作的 2 sklearn.svm.SVC2.1 线性SVM决策过程的可视化2.2 重要参数kernel(核函数)2.3 探索核函数在不同数据集上的表现2.4 探索核函数的优势和缺陷2.5 选取与核函数相关的参数:degree & gamma…
【Sklearn】基于梯度提升树算法的数据分类预测(Excel可直接替换数据)
【Sklearn】基于梯度提升树算法的数据分类预测(Excel可直接替换数据) 1.模型原理2.模型参数3.文件结构4.Excel数据5.下载地址6.完整代码7.运行结果1.模型原理
梯度提升树(Gradient Boosting Trees)是一种集成学习方法,用于解决分类和回归问题。它通过将多个弱学习器(通常…
RandomForest之RandomForestRegressor参数详解以及调参
RandomForest之RandomForestRegressor参数详解以及调参 一、参数、属性及方法1、参数(1)n_estimators(2)criterion(3)max_depth(4)min_samples_split(5)min_samples_leaf(6)min_weight_fraction_leaf(7)max_features(8)max_leaf_nodes(9)min_impurity_split(…
记录踩过的坑-sklearn
目录
安装
使用逻辑回归报错:STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
内置的MNIST数据集
sklearn中的svm
sklearn中的svm训练太慢 安装
pip install scikit-learn 使用逻辑回归报错:STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
增加迭代…
sklearn中Naive Bayes的原理及使用案例
大家好,今天本文将介绍sklearn中Naive Bayes的原理及使用案例。
一、Naive Bayes的原理
朴素贝叶斯(Naive Bayes)是一种基于贝叶斯定理的分类算法,它假设所有特征之间相互独立,即给定类别的情况下,特征之…
机器学习笔记 - 异常检测之OneClass SVM算法简述
一、异常检测是什么? 如下图,理想中我们可以找到一个框住大部分正常样本的决策边界,而在边界外部的数据点(蓝点)即视为异常。 但实际情况下数据都没有标签,因此很难定义正常还是不正常。异常检测的主要挑战如下:正常与异常行为之间的界限往往并不明确、不同的应…
SVM支持向量机-SKlearn实现与绘图(8)
了解了SVM的基本形式与算法实现,接下来用SKlearn实现支持向量机分类器.
1.函数定义与参数含义
先看一下SVM函数的完全形式和各参数含义:
SVC(C1.0, kernel’rbf’, degree3, gamma’auto’, coef00.0, shrinkingTrue, probabilityFalse, tol0.001, ca…

sklearn中的聚类算法K-Means
1 概述
1.1 无监督学习与聚类算法
决策树、随机森林、逻辑回归虽然有着不同的功能,但却都属于“有监督学习”的一部分,即是说,模型在训练的时候,既需要特征矩阵XXX,也需要真实标签yyy。在机器学习中,还有…
python sklearn模块提示ImportError: cannot import name datasets
报错原因很简单,因为我的文件名叫sklearn,然后系统就屏蔽了真正的sklearn,所以改下名字就行了
自然数编码:sklearn.preprocessing.LabelEncoder
文章目录1 介绍LabelEncoder2 作用3 代码举例4 代码举例21 介绍LabelEncoder
在训练模型之前,需要对数据进行处理,比如说分类,进行类别编号。
举例:把“男”、“女”编号为“0”和“1”。2 作用
把 n 个类别编码为 0 ~ n-1 之间…
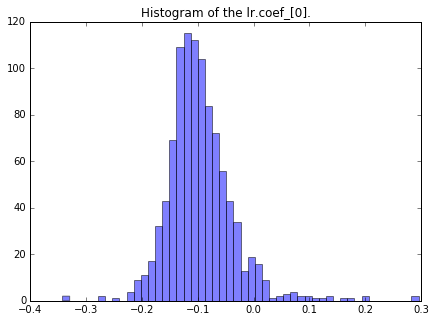
scikit-learn : 线性回归模型性能评估
背景
在这个主题中,我们将介绍回归模型拟合数据的效果。每当用线性模型拟合数据做完之后,我们应该问的第一个问题就是“拟合的效果如何?”本主题将回答这个问题。
线性模型
我们还用上一主题里的lr对象和boston数据集。lr对象已经拟合过数…
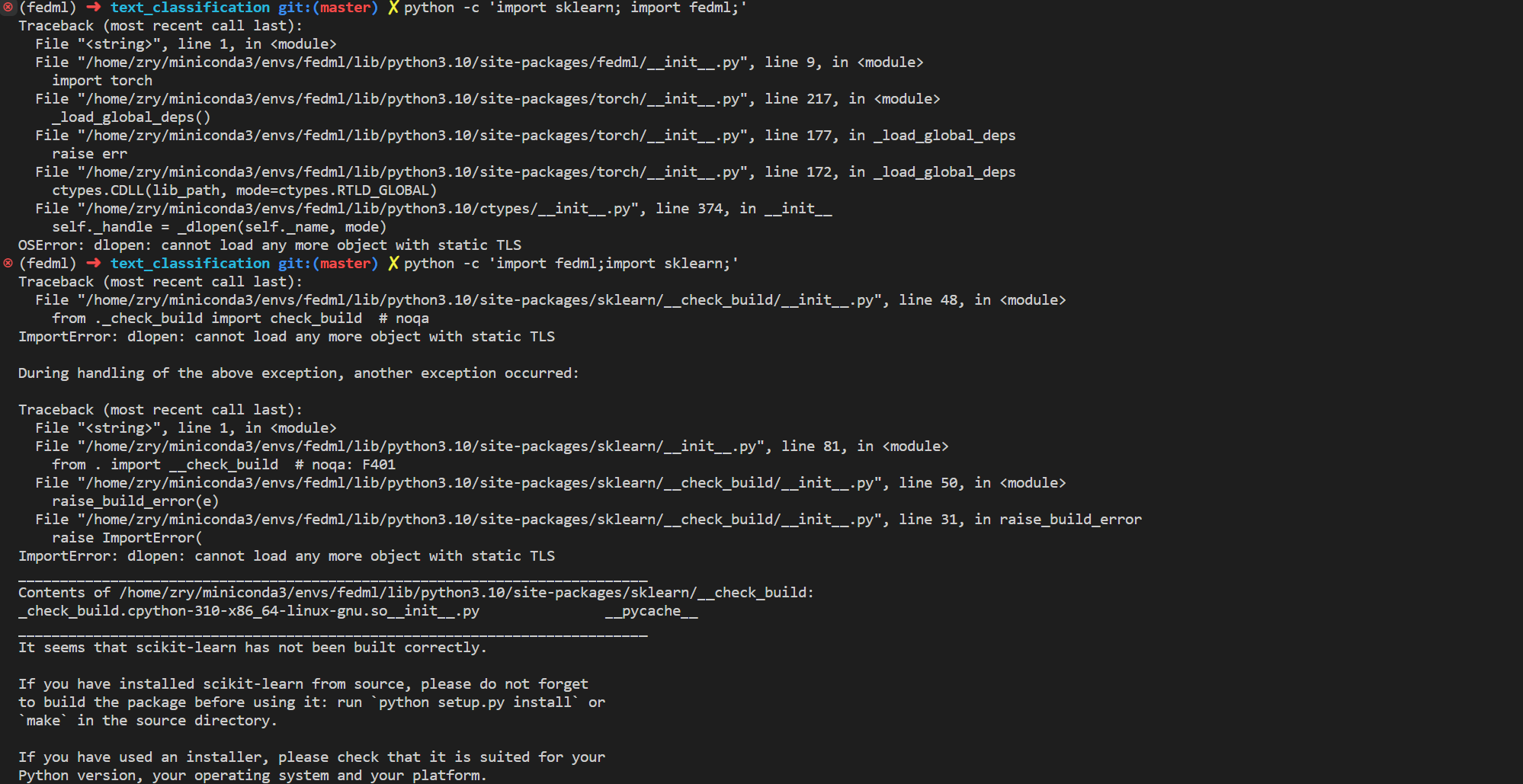
python 包引入顺序错误:torch sklearn fedml
今天遇到的这个问题真的是奇葩,新年的第一个奇葩问题。 # 正常的引入错误
python -c import torch; import sklearn; import fedml;# 错误的引入错误
python -c import fedml;import sklearn;
python -c import sklearn; import fedml;
python -c import fedml;impo…

论文阅读 Graph-Based Global Reasoning Networks
Graph-Based Global Reasoning Networks
论文题目:基于图结构的全局推理网络 会议:CVPR 2018 作者单位:脸书研究院 新加坡国立大学 作者: Chen Yunpeng 代码:https://github.com/NUST-Machine-Intelligence-Laborator…

机器学习 scikit-learn GridSearchCV scoring 参数设置
创建于:20211011 修改于:20211011 文章目录1、分类2、聚类3、回归4、参考资料本文来源于官网:3.3. Metrics and scoring: quantifying the quality of predictions
Scoring parameter: Model-evaluation tools using cross-validation (such…
(实战)sklearn----多元线性回归sklearn----多项式回归
import numpy as np
from numpy import genfromtxt
from sklearn import linear_model
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D # 读入数据
data genfromtxt(r"Delivery.csv",delimiter,)
print(data)# 切分数据
x_data dat…

sklearn——一元线性回归
from sklearn.linear_model import LinearRegression
import numpy as np
import matplotlib.pyplot as plt# 载入数据
data np.genfromtxt("data.csv", delimiter",")
x_data data[:,0]
y_data data[:,1]
plt.scatter(x_data,y_data)
plt.show()
print…
吴恩达 deeplearning.ai - 神经网络和深度学习 - 第三周代码
参考链接:https://blog.csdn.net/u013733326/article/details/79702148
准备软件包
我们需要准备一些软件包:
numpy:是用Python进行科学计算的基本软件包。sklearn:为数据挖掘和数据分析提供的简单高效的工具。matplotlib &…
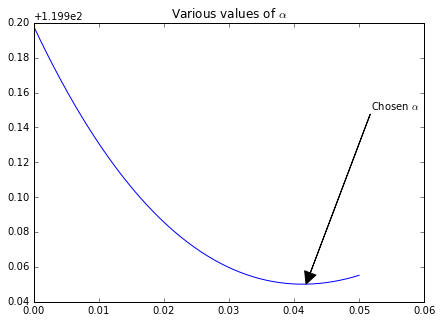
scikit-learn : 优化岭回归参数alpha优化
背景:优化岭回归参数alpha
当你使用岭回归模型进行建模时,需要考虑Ridge的alpha参数。
例如,用OLS(普通最小二乘法)做回归也许可以显示两个变量之间的某些关系;但是,当alpha参数正则化之后&am…

一文简述如何使用嵌套交叉验证方法处理时序数据 @ 机器之心
本文讨论了对时序数据使用传统交叉验证的一些缺陷。具体来说,我们解决了以下问题:
1)在不造成数据泄露的情况下,对时序数据进行分割;2)在独立测试集上使用嵌套交叉验证得到误差的无偏估计;3&am…

sklearn岭回归
文章目录 基本原理sklearn实现 基本原理
最小二乘法的判定条件是 min w ∥ X w − y ∥ 2 2 \min_w\Vert Xw-y\Vert_2^2 wmin∥Xw−y∥22
其中, min w F ( w ) \min_w F(w) minwF(w)表示 F ( w ) F(w) F(w)最小时的 w w w; w w w是拟合参数…
机器学习——线性回归、房价预测案例【正规方案与梯度下降】
# coding:utf-8 # 1.获取数据集 #2.数据基本处理 #2.1.数据划分 #3.特征工程——标准化 #4.机器学习(线性回归) #5.模型评估 from sklearn.datasets import load_boston # 1.获取数据集,所使用的引用 from sklearn.model_selection import train_test_sp…

如何划分训练集和测试集
sklearn.model_selection中train_test_split()函数
train_test_split()是sklearn.model_selection中的分离器函数,用于将数组或矩阵划分为训练集和测试集,函数样式为: X_train, X_test, y_train, y_test train_test_split(train_data, trai…
cuml机器学习GPU库 sklearn升级版AutoDL使用
CUML库
最近在做机器学习任务的时候发现我自己的数据集太大,直接用sklearn 跑起来时间很长,然后问GPT得知了有CUML库,后来去研究了一下,发现这个库只支持linux系统,从官网直接获取下载命令基本上也实现不了最后&#…

多元线性回归改进RidgeLasso
多元线性回归改进 – 潘登同学的Machine Learning笔记 文章目录多元线性回归改进 -- 潘登同学的Machine Learning笔记(简单回顾)多元线性回归模型归一化normalization归一化的方法来个小例子试一试?正则化regularization正则项Lasso回归 和 Ridge岭回归L1稀疏L2平滑…
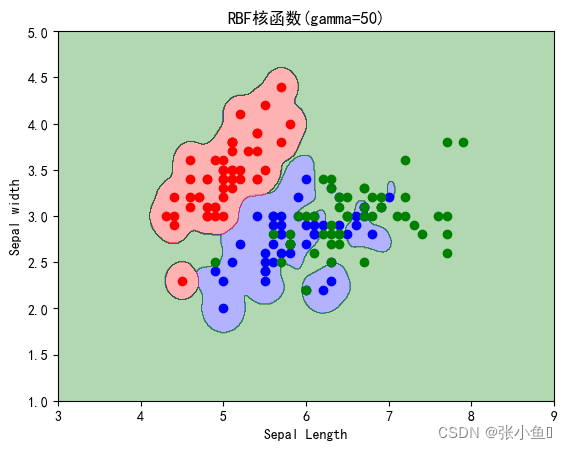
机器学习之SVM分类器介绍——核函数、SVM分类器的使用
系类文章目录
机器学习算法——KD树算法介绍以及案例介绍
机器学习的一些常见算法介绍【线性回归,岭回归,套索回归,弹性网络】
文章目录
一、SVM支持向量机介绍
1.1、SVM介绍
1.2、几种核函数简介
a、sigmoid核函数 b、非线性SVM与核函…
StratifiedKFold 函数介绍
目录
1、定义
2、具体步骤
3、主要优点
4、示例代码
1、定义
StratifiedKFold 是一种交叉验证方法,用于在机器学习任务中对数据集进行划分。它是对KFold方法的改进,特别适用于样本不平衡的情况。在 StratifiedKFold 中,数据集被划分为k…
保存训练好的机器学习模型
保存训练好的机器学习模型当我们训练好一个model后,下次如果还想用这个model,我们就需要把这个model保存下来,下次直接导入就好了,不然每次都跑一遍,训练时间短还好,要是一次跑好几天的那怕是要天荒地老了。…
GridSearchCV 工具介绍
目录
1、定义
2、工作流程
3、示例代码
4、总结
1、定义
GridSearchCV 是一个用于超参数调优的工具,它在给定的参数网格中执行交叉验证,以确定最佳的参数组合。通过穷举搜索(exhaustive search)来寻找最佳参数,即…

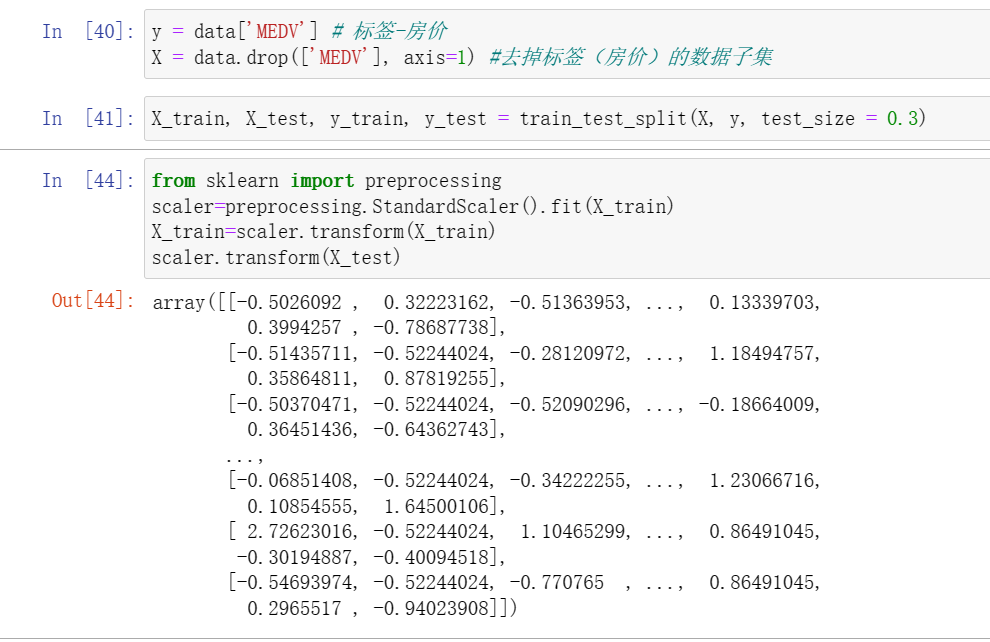
python基础学习9【MinMaxScale()、StandScale()、DecimalScale、transformer】
标准化数据【离差标准化数据、标准差标准化数据、小数定标标准化数据】
离差标准化数据: 数据的整体分布情况并不会随离差标准化而发生改变,原先取值较大的数据,在做完离差标准化后的值依旧较大;
对原始数据的一种线性变换&…
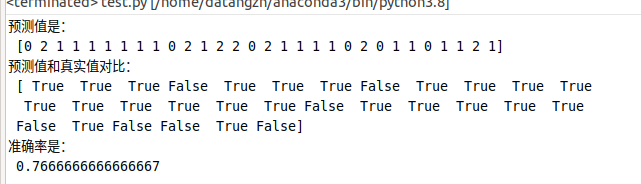
机器学习—K近邻算法(knn)【适合于大样本的自动分类】
Created on 2022年1月16日 1.获取数据集 2.数据基本处理 3.特征工程 4.机器学习(模型训练) 5.模型评估 author: datangzn from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler f…
【已解决】No module named ‘sklearn‘
问题描述 No module named ‘sklearn‘ 解决办法
pip install scikit-learn
完结撒花 契约、包容、感恩、原则……这些成年人该有的基本精神,为什么我在他们身上找不到呢?

LASSO算法(实战)sklearn----LASSO算法
import numpy as np
from numpy import genfromtxt
from sklearn import linear_model# 读入数据
data genfromtxt(r"longley.csv",delimiter,)
print(data)# 切分数据
x_data data[1:,2:]
y_data data[1:,1]
print(x_data)
print(y_data)# 创建模型
model line…
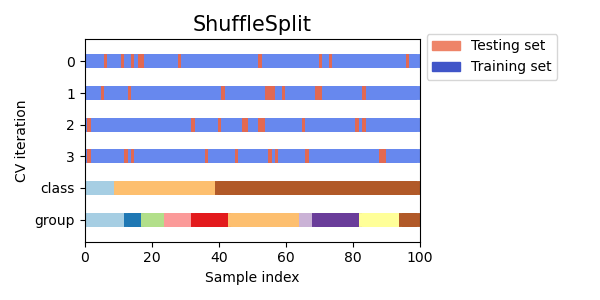
ML@sklearn@ML流程Part2@数据划分@KFold折叠交叉验证
文章目录 MLsklearnML流程Part2数据划分KFold折叠交叉验证Model evaluation数据划分sklearn中的模型评估demo K-fold cross-validation🎈K-foldegegeg:KFoldK-fold cross-validation ShuffleSpliteg 小结 Stratified Shuffle Splitegeg demo MLsklearnML流程Part2数…
sklearn模型保存
from sklearn import svm
from sklearn import datasets
import pickle # 保存模块clf svm.SVC()
iris datasets.load_iris()
x, y iris.data, iris.target
clf.fit(x, y)
"""方法一:使用 pickle 保存"""
# 保存Model(注:save文件夹要预先建…
sklearn模型属性与方法
from sklearn import datasets
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as pltloaded_data datasets.load_boston()
data_x loaded_data.data
data_y loaded_data.targetmodel LinearRegression()
# model.fit 用来训练模型
model.fi…
机器学习——逻辑回归、肿瘤预测案例(恶性乳腺)
# coding:utf-8 # 1.获取数据集 #2.数据基本处理 #2.1.数据划分 #3.特征工程——标准化 #4.机器学习(逻辑回归) #5.模型评估 import pandas as pd import numpy as np # 1.获取数据集,引用网上数据https://archive.ics.uci.edu/ml/machine-learning-data…
深度學習之多層感知器(MLP)之經典mnist數字識別
目录前言簡介思考與推導實戰總結前言
在上一篇文章中用mlp解决了一个好壞質檢二分類问题,这次我们依然用多層感知器mlp来解决經典mnist數字識別 回顧一下前文,但是具體理論還是看前文深度學習之多層感知器(MLP) 簡介
多层感知器…
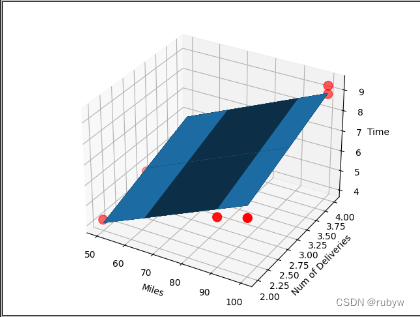
Python多元线性回归sklearn
# -*- coding: utf-8 -*-
"""
Created on 2024.1.22author: rubyw
"""import numpy as np
from numpy import genfromtxt
from sklearn import linear_model
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D# 读入数据…

sklearn中的支持向量机SVM(上)
1 概述
支持向量机(SVM,也称为支持向量网络),是机器学习中获得关注最多的算法。它源于统计学习理论,是除了集成学习算法之外,接触到的第一个强学习器。 从算法的功能来看,SVM囊括了很多其他算法…

【机器学习】sklearn的集成学习用于图像分类从0到1,注意点和坑点
文章目录 前言1.需求分析1.1 场景1.2 解决方案 2. 代码2.1 提取特征2.2 构建分类器2.4 集成模型2.5 总的训练代码 3.fast api 封装4.总结 前言
深度学习崛起后,好像机器学习就没落了,但在固定场景下,还是很好用的。下面就是展厅项目的识别任…

9.sklearn——logistic regression 参数解释 及 案例
文章目录1. 函数2. 参数解释3. 实例1. 函数
首先了解使用到的函数的参数含义。有两种途径:
一种是在IDE中输入help("函数名")。直接在ide中调出了官方文档。另一种是直接在网上搜sklearn官方文档,在里面找到自己需要的这个函数。
第一种方法࿱…
机器学习sklearn.metrics.pairwise.rbf_kernel介绍
使用: sklearn.metrics.pairwise.rbf_kernel(X, YNone, gammaNone) 介绍: 计算X和Y之间的rbf(高斯)内核:
K(x, y) exp(-gamma ||x-y||^2)参数说明Xarray of shape (n_samples_X, n_features)Yarray of shape (n_samp…
【sklearn练习】模型评估
一、交叉验证 cross_val_score 的使用
1、不用交叉验证的情况:
from __future__ import print_function
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifieriris…

Polynomial多项式升维和PCA降维
Polynomial多项式升维和PCA降维 --潘登同学的Machine Learning笔记 文章目录Polynomial多项式升维和PCA降维 --潘登同学的Machine Learning笔记(简单回顾)多元线性回归模型Polynomial多项式升维多项式升维具体操作(以两个变量为例)PCA降维特征向量中刻画了矩阵的本质PCA目标PCA…
如何将python训练的XGBoost模型部署在C++环境推理
当前环境:Ubuntu,xgboost1.7.4过程介绍:首先用python训练XGBoost模型,在训练完成后注意使用xgb_model.save_model(checkpoint.model)进行模型的保存。找到xgboost的动态链接库和头文件动态链接库:如果你在conda环境下面…

(实战)梯度下降法——非线性逻辑回归sklearn——非线性逻辑回归
数据集
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import classification_report
from sklearn import preprocessing
from sklearn.preprocessing import PolynomialFeatures
# 数据是否需要标准化
scale False# 载入数据
data np.genfro…

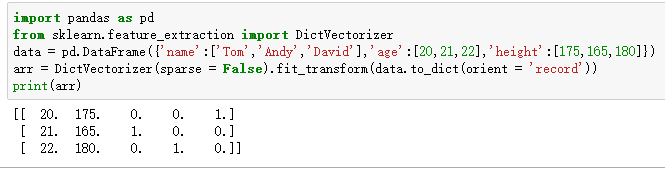
机器学习——英文特征提取,中文特征提取
环境:ubuntu20.10,python3.8
代码如下:
#coding:utf-8 from sklearn.feature_extraction import DictVectorizer, stop_words from sklearn.feature_extraction.text import CountVectorizer import jieba def dict_demo(): #"""&q…

1.关于scikit-learn简介
说明:这个sklearn系列的笔记,在我的分类scikit-learn里面,主要介绍常用的模型的参数,并且附带数据、案例、代码、结果。
这个系列的笔记不会限于sklearn,还会包括一些时间序列(StatsModels)、词…

semi-supervised learning
半监督学习[1]
当根据手头仅有的标注数据,会将一些虽然没有标注但可被观测到的数据进行一些合理的推测,其中推测主要基于两个假设:
聚类假设cluster assumption:假设数据间具有相同的聚类结构,同一类数据会落入同一个…
【教学类-40-01】A4骰子纸模制作(点数是不同的符号图案)
作品展示 背景需求
骰子是孩子们喜欢的游戏玩具,大3班两个孩子用纸条做了两个迷你的骰子。
所以我想在A4纸上做一个骰子的纸模。 素材准备 WORD模板 隐藏线条、设置实线、虚线、粗线等,慢慢调整,很繁琐
目的:
1、骰子 点数是不…


【统计学习方法】2021-10-01-统计学习方法学习记录(一)【章节一:统计学习与监督学习概论(1)】
【这是我第一次阅读统计学习方法这本书,就目前的情况来看由于知识储备的限制我这一次可能只能止步于理解而难以撑得过进一步追问,希望我在数理和编程能力上去之后会变的好一些吧】 【原本想把第一章全部写在一篇里,但是上次写数字设计的第一章…
网格搜索GridSearchCV参数方法详细解析
机器学习中GridSearchCV网格搜索的参数、方法 1、简介2、参数(1)estimator: estimator object(2)param_grid: dict or list of dictionaries(3)scoring: str, callable, list, tuple or dict, default=None(4)n_jobs: int, default=None(5)refit: bool, str, or call…

逻辑回的阈值0.5修改问题
逻辑回归阈值修改
#使用sklearn乳腺癌数据集验证
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression as LR
import numpy as np
np.set_printoptions(suppressTrue)data load_breast_cancer()lr LR().fit(data.data,da…
sklearn缺失值处理:SimpleImputer模块 补全缺失值
文章目录 SimpleImputer参数详解参数含义常用方法sklearn.impute工具介绍SimpleImputer参数详解
class sklearn.impute.SimpleImputer(*, missing_values=nan, strategy=‘mean’, fi
sklearn——转换器(Transformer)与预估器(estimator)
sklearn——转换器(Transformer)与预估器(estimator) 文章目录sklearn——转换器(Transformer)与预估器(estimator)转换器 Transformerfit 与 fit_transform 与 transform值得注意的…
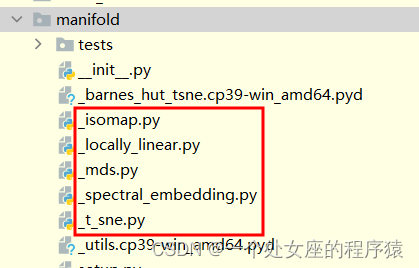
ML之DR:sklearn.manifold(流形学习和降维的算法模块)的简介、部分源码解读、案例应用之详细攻略
ML之DR:sklearn.manifold(流形学习和降维的算法模块)的简介、部分源码解读、案例应用之详细攻略 目录
sklearn.manifold的简介
sklearn.manifold(流形学习和降维的算法模块)的概述
外文翻译
sklearn.manifold的部分源码解读 sklearn.manifold的简介
sklearn.ma…
【Python机器学习】sklearn.datasets其他通用函数
为什么了解Sklearn中的其他或通用数据集和函数这么重要?
在数据科学和机器学习的世界里,数据是一切的基础。但获取和处理数据通常都是一项非常耗时和复杂的任务。这时,sklearn.datasets模块就显得尤为重要。除了为分类和回归任务提供数据集外,该模块还有一些“其他或通用”…
决策树算法及Python实现
1 什么是决策树 决策树(Decision Tree)是一种基本的分类与回归方法,本文主要讨论分类决策树。决策树模型呈树形结构,在分类问题中,表示基于特征对数据进行分类的过程。它可以认为是if-then规则的集合。每个内部节点表示…
sklearn.preprocessing 标准化、归一化、正则化
文章目录 数据标准化的原因作用归一化最大最小归一化针对规模化有异常的数据标准化线性比例标准化法log函数标准化法正则化Normalization标准化的意义数据标准化的原因 某些算法要求样本具有零均值和单位方差;需要消除样本不同属性具有不同量级时的影响:
① 数量级的差异将导…

sklearn数据集操作2
可在线下载(Downloadable)的数据集 sklearn.datasets.fetch_ 20类新闻文本数据集: 该数据集包含了关于20个话题(topic)的18000条新闻报道,这些数据被分为两个子集:训练集和测试集。 20组新闻文本数据集API用法详解 …
sklearn模型指标和特征贡献度查看
文章目录 算法介绍r2_scoretrain_test_splitDecisionTreeRegressor参考文献支持快速查看traget和特征之间的关系 # -*- coding: utf-8 -*-
import pandas as pd
pd.set_option(display.max_columns, None)
pd.set_option
sklearn 笔记 BallTree/KD Tree
由NearestNeighbors类包装
1 主要使用方法
sklearn.neighbors.BallTree(X, leaf_size40, metricminkowski, **kwargs)
X数据集中的点数leaf_size改变 leaf_size 不会影响查询的结果,但可以显著影响查询的速度和构建树所需的内存metric用于距离计算的度量。默认为…
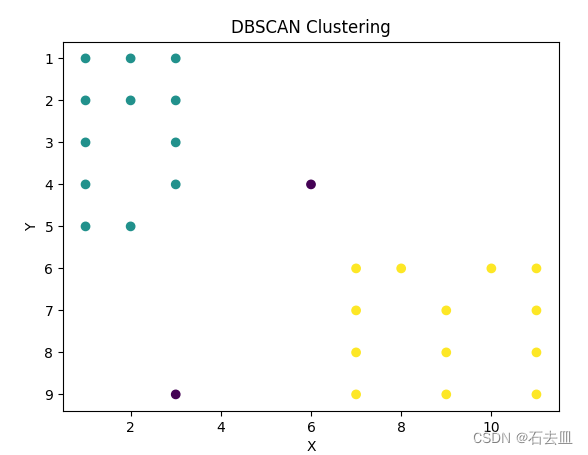
数据挖掘题目:设ε= 2倍的格网间距,MinPts = 6, 采用基于1-范数距离的DBSCAN算法对下图中的实心格网点进行聚类,并给出聚类结果(代码解答)
问题 代码
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import DBSCAN
#pip install matplotlib
#pip install numpy
#pip install scikit-learn
# 实心格网点的坐标
solid_points np.array([[1, 1], [2, 1],[3, 1], [1, 2], [2, 2], [3, 2],[…
logistic回归-(sklearn)参数含义及实现(3)机器学习实战
经过前两篇的介绍,相信对logistic回归分类已经有一些了解了,下面我们用书上的例子,使用之前的代码和sklearn的库函数解决,看看效果怎么样。 示例:从疝气疾病预测病马的死亡率
1.书中代码实现
这里先导入两个上篇文章…
使用sklearn报AttributeError: ‘NoneType‘ object has no attribute ‘split‘
错误原因
在使用scikit-learn的时候报AttributeError: NoneType object has no attribute split Exception ignored on calling ctypes callback function: <function _ThreadpoolInfo._find_modules_with_dl_iterate_phdr..match_module_callback at 0x7fb757978160> T…

Python机器学习库scikit-learn在Anaconda中的配置
本文介绍在Anaconda环境中,安装Python语言scikit-learn模块的方法。 scikit-learn库(简称sklearn)是一个基于Python语言的机器学习库,提供了各种机器学习算法和相关工具,包括分类、回归、聚类、降维、模型选择和预处理…

mac安装sklearn一直提示Installing build dependencies ...这个问题
解决方案:
pip install --pre --extra-index https://pypi.anaconda.org/scipy-wheels-nightly/simple scikit-learn
关于为什么sklearn画出来的ROC曲线图是折线的问题
经过
师兄的提醒,我将单一值的标签图用最初的概率图进行替换。 不要扯什么这个那个,就是不能用阈值去将概率图变成最终的分割图,那个阈值就是ROC曲线图中需要的,我们只要提供模型分割的概率图即可。
评论区中有小伙伴不理解这个…
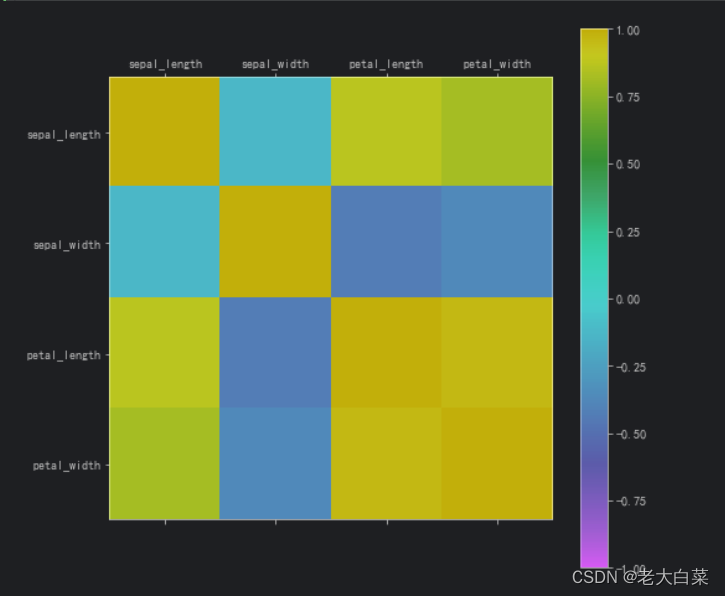
sklearn 中皮尔森相关性。
相关性
import pandas as pd
from pandas import set_option
irispd.read_csv(data/iris.csv)
set_option(precision, 2) # 设置数据的精确度
iris.corr(methodpearson) # 皮尔森相关性correlations iris.corr(methodpearson)
names correlations.columns.tolist()
fig plt…
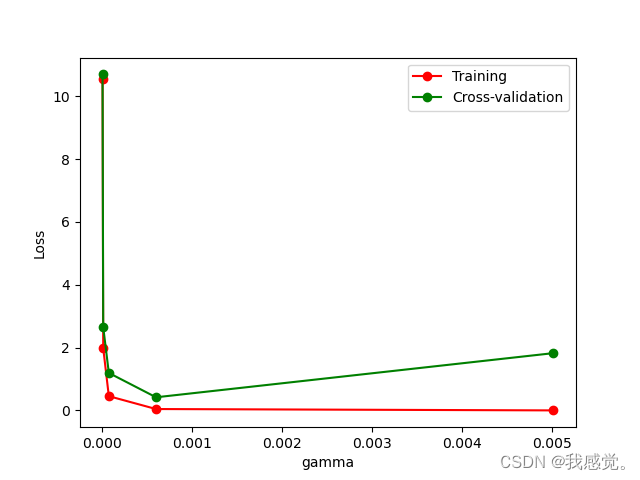
【xgboost】XGBoost 调参
1. 原生api 训练、网格搜索1.1 数据1.2 设置参数 & 训练1.3 网格搜索调参1.3.1 外套sklearn api⭐⭐⭐1.3.2 自定义目标函数1.3.3 设置搜索参数 & 初次搜索1.3.4 确定部分参数 & 进一步搜索 1.4 循环、交叉验证调参 2. sklearn api 调参2.1 数据2.2 网格搜索2.3 op…

sklearn模型选择与评估
数据集划分方法 数据集划分方法:k折交叉验证 这个方法充分利用了所有样本。但是计算比较繁琐,需要训练k次,测试k次。
数据集划分法:留一法 留一法与k折交叉比较 留P法验证 数据集划分方法:随机划分法
1、【特征抽取(NLP)】机器学习之特征工程和文本特征的提取
常用数据集构成 = 特征值 + 目标值(0/1)每一行为一条记录,每一列即为一个特征对特征值进行处理: pandas进行简单处理(主要是对缺失值数据,重复值不用处理);特征工程之特征抽取:
对文本数据进行特征值化(即转换为数值数据):sklearn.feature_extraction 对字典数据进…

线性回归api再介绍
1 线性回归api再介绍 2. 案例:波⼠顿房价预测
2.1 案例背景介绍 2.2. 案例分析
回归当中的数据⼤⼩不⼀致,是否会导致结果影响较⼤。所以需要做标准化处理。
数据分割与标准化处理回归预测线性回归的算法效果评估
2.3 回归性能评估 2.4 代码实现
正…
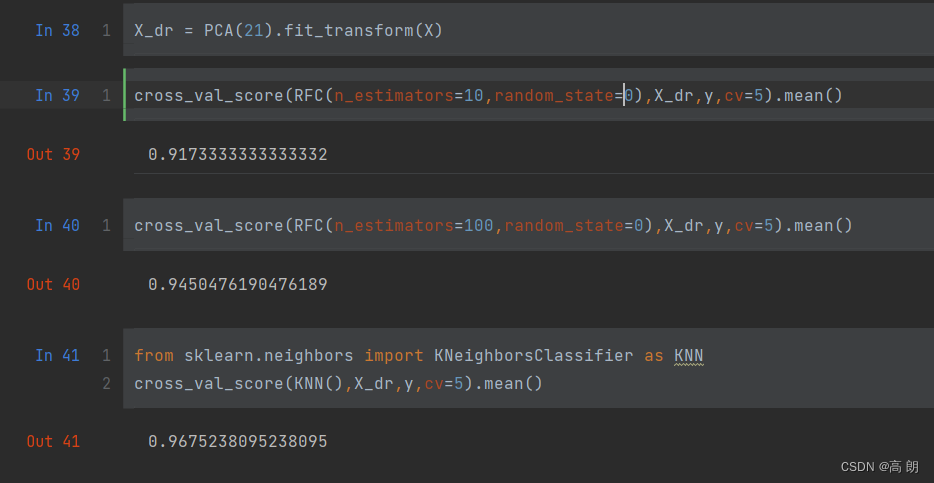
【机器学习】sklearn降维算法PCA
文章目录 降维PCAsklearn中的PCA代码实践 PCA对手写数字数据集的降维 降维
如何实现降维?【即减少特征的数量,又保留大部分有效信息】 将那些带有重复信息的特征合并,并删除那些带无效信息的特征等等,逐渐创造出能够代表原特征矩…
【Sklearn】基于逻辑回归算法的数据分类预测(Excel可直接替换数据)
【Sklearn】基于逻辑回归算法的数据分类预测(Excel可直接替换数据) 1.模型原理2.模型参数3.文件结构4.Excel数据5.下载地址6.完整代码7.运行结果1.模型原理
逻辑回归是一种用于二分类问题的统计学习方法,尽管名字中含有“回归”,但实际上是一种分类算法。它的基本原理是通…
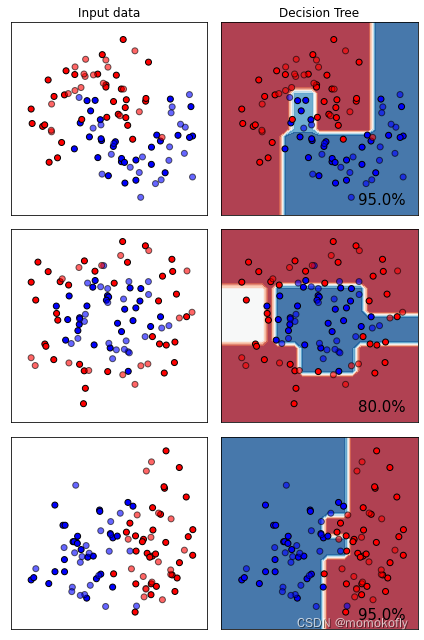
sklearn入门决策树在sklearn中的实现
sklearn入门
scikit-learn官网:http://scikit-learn.org/stable/index.html 中文翻译网址:https://sklearn.apachecn.org/docs/master/2.html 算法原理推荐书籍:《数据挖掘导论》、《机器学习》
决策树
1 概述
非参数的有监督学习方法&am…

Python数据分析:逻辑回归(logistic regression)
Python数据分析:逻辑回归(logistic regression)
逻辑回归(Logistic Regression),简称LR,能够将特征输入集合转化为0和1这两类的概率。
优点:计算代价不高,易于理解和实现缺点:容易…
对鸢尾花进行分类预测-----pycharm
项目说明
#项目: 对鸢尾花进行分类预测
#实例数量150个(3类各50个)
#属性数量:4(数值型,数值型,帮助预测的属性和类)
#特征:花萼长度,花萼宽度,花瓣长度,花瓣宽度 单位࿱…
pyinstaller打包xgboost项目,得到的可执行文件运行出错
问题描述:
用pyinstaller打包xgboost项目,打包过程没有出错,但运行得到的可执行文件时,报出如下错误(直接运行python工程并不会报这个错):
super() has no attribute get_params, sklearn.py,…
sklearn 中ShuffleSplit()函数详细解
作用
ShuffleSplit()函数是交叉验证中的一种分割数据集的方法。它的作用是将原始数据集随机打乱,并按照指定的比例将数据集划分为训练集和测试集。 具体来说,ShuffleSplit()函数会将数据集中的样本随机打乱,并根据设定的参数生成多个不重叠的…

sklearn处理离散变量的问题——以决策树为例
最近做项目遇到的数据集中,有许多高维类别特征。catboost是可以直接指定categorical_columns的【直接进行ordered TS编码】,但是XGboost和随机森林甚至决策树都没有这个接口。但是在学习决策树的时候(无论是ID3、C4.5还是CART)&am…

【机器学习】sklearn特征值选取与处理
sklearn特征值选取与处理 文章目录 sklearn特征值选取与处理1. 调用数据集与数据集的划分2. 字典特征选取3. 英文文本特征值选取4. 中文特征值选取5. 中文分词文本特征抽取6. TfidfVectorizer特征抽取7. 归一化处理8. 标准化处理9. 过滤低方差特征10. 主成分分析11. 案例&#…
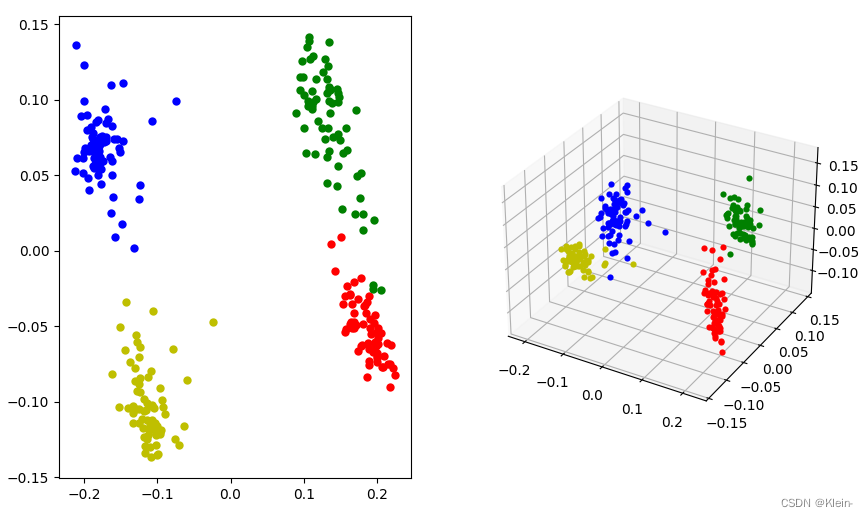
高维数据PCA降维可视化(KNN分类)
在做机器学习的时候,经常会遇到三个特征以上的数据,这类数据通常被称为高维数据。数据做好类别分类后,通过二维图或者三维图进行可视化,对于高维数据可以通过PCA(Principal Component Analysis),即主成分分析方法&…
2.机器学习-算法1
文章目录1.转换器与预估器1.转换器2 估计器(sklearn机器学习算法的实现)3 估计器工作流程2.K-近邻算法1 什么是K-近邻算法2.模型选择与调优3 用KNN算法对鸢尾花进行分类4 用KNN算法分类,添加网格搜索和交叉验证5 facebook案例5 小结3 朴素贝叶斯算法1 什么是朴素贝叶…

python中sklearn库在数据预处理中的详细用法,及5个常用的Scikit-learn(通常简称为 sklearn)程序代码示例
文章目录 前言1. 数据清洗:使用 sklearn.preprocessing 中的 StandardScaler 和 MinMaxScaler 进行数据规范化。2. 缺失值处理:使用 sklearn.impute 中的 SimpleImputer 来填充缺失值。3. 数据编码:使用 sklearn.preprocessing 中的 OneHotEn…

pytorch+sklearn实现数据加载
之前在训练网络的时候加载数据都是稀里糊涂的放进去的,也没有理清楚里面的流程,今天整理一下,加深理解,也方便以后查阅。 pytorchsklearn实现数据加载epoch & batch_size & iteration优化算法——梯度下降Batch gradient …
自制机器学习工具库源码解释(KNN线性回归)
欢迎大家提出宝贵意见源码:简易KNN网格搜索版KNN正则版线性回归梯度下降版线性回归:防止重复库安装方法以及更新命令安装更新测试代码以及截图(部分)KNN&鸢尾花线性回归&波士顿房价预测源码:
由于刚开始写&am…
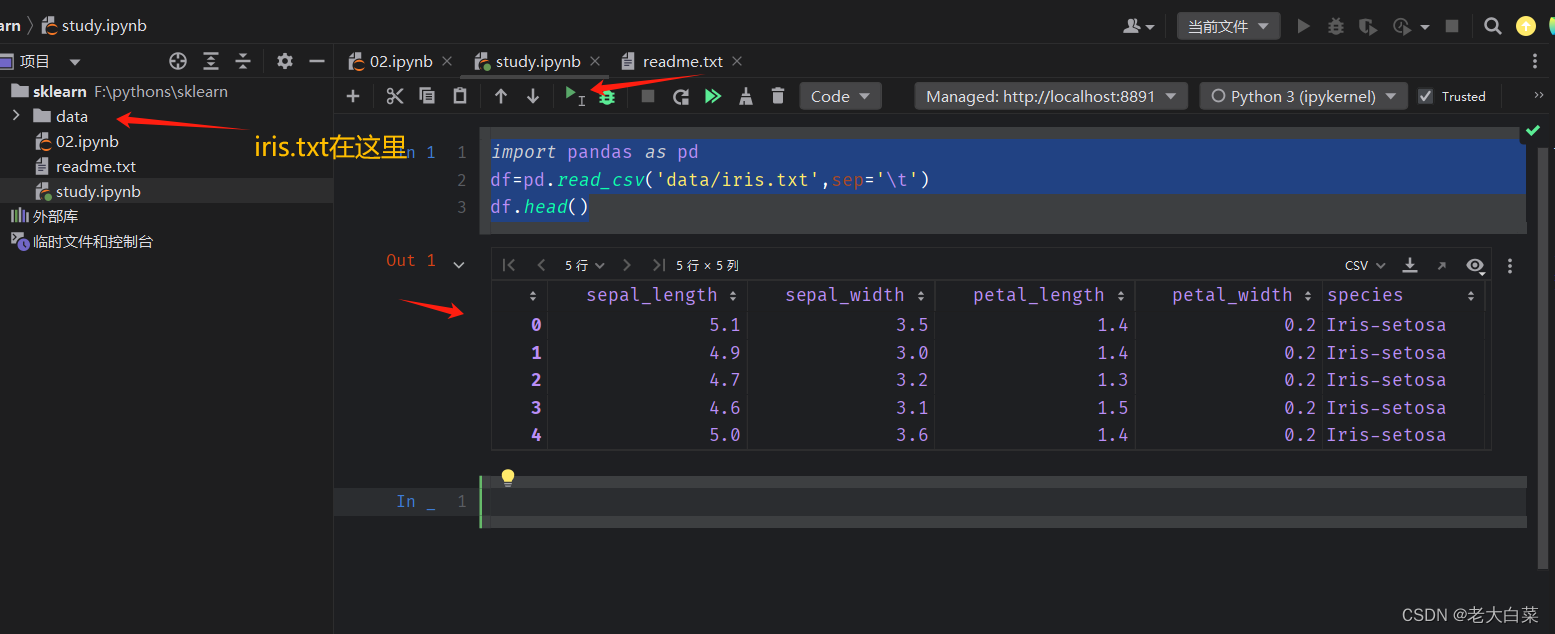
sklearn学习的一个例子用pycharm jupyter
环境
运行在jupyter 进行开发。即一个WEB端的开发工具。能适时显示开发的输出。后缀用的是ipynb.pycharm也可以支持。但也要提示按装jupyter. 或直接用andcoda 这里我们用pycharm进行项目创建
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple jupyterlab
pip ins…

关于sklearn的:还可能是网络的问题???
前提:安装sklearn需要 numpy、scipy等库(这个自行搜索) 昨天安装numpy、scipy很快,一会就好了,然后安装sklearn一直报错,还以为是版本问题。
今天大早上起来,再次安装,顺利成功&…
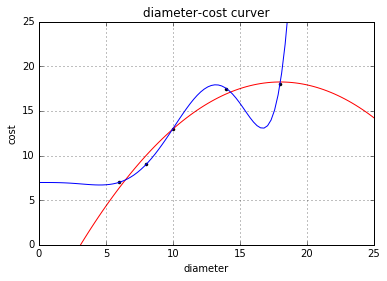
scikit-learn : 线性回归,多元回归,多项式回归
匹萨的直径与价格的数据
%matplotlib inline
import matplotlib.pyplot as plt
def runplt():plt.figure()plt.title(udiameter-cost curver)plt.xlabel(udiameter)plt.ylabel(ucost)plt.axis([0, 25, 0, 25])plt.grid(True)return pltplt runplt()
X [[6], [8], [10], [14]…

机器学习对数据缺失值的处理方法
两种处理办法
(1)删除:首先如果这一列或者一列的数据缺失值达到一定程度,建议放弃整行或整列。
(2)一般我们建议做插补:
可以通过缺失值的每行或者每列的平均值、中位数进行填充。࿰…
sklearn:机器学习 分类特征编码category_encoders
文章目录 category_encoders简介OrdinalEncoder 序列编码OneHotEncoder 独热编码TargetEncoder 目标编码Binary Encoder 二进制编码BaseNEncoder 贝叶斯编码LeaveOneOutEncoder 留一法HashingEncoder 哈希编码CatBoostEncoder catboost目标编码CountEncoder 频率编码WOEEncoder…

sklearn手册(持续更新ing...)
诸神缄默不语-个人CSDN博文目录
本文是一个随时使用sklearn时可供参考的手册。我有使用sklearn的基础,且准备后期直接用sklearn官方的教程文档参考撰写系统性学习sklearn包使用方法的sklearn用户教程一文,因此本文就不介绍基础了。
最近更新时间&#…

【办公类-19-01】20240108图书统计登记表制作(23个班级)EXCEL复制表格并合并表格
背景需求:
制作一个EXCEL模板,每个班级的班主任统计 班级图书量(一个孩子10本,最多35个孩子350本)
EXCEL模板 1.0版本:
将这个模板制作N份——每班一份 项目:班级图书统计表
核心:一个EXCEL模板批量生成…
决策树 {Keras 由浅入深}
决策树
TensorFlowKerassklearn
python & mathematics 决策树是基于区域(region-based)的机器学习方法,是非线性的。 主要用于为集合进行分配,达到分配的子集的并为全集,各子集互不相交 即: χ∪i0nRi…
【已解决】ModuleNotFoundError: No module named sklearn
这个问题比较简单,就简单记录如下: "ModuleNotFoundError: No module named sklearn" 错误表示你尝试导入名为 "sklearn" 的Python模块,但Python解释器找不到该模块。这通常是因为你尚未安装所需的Python库或模块。要解决…
sklearn和tensorflow的理解
人工智能的实现是基于机器学习,机器学习的一个方法是神经网络,以及各种机器学习算法库。
有监督学习:一般数据构成是【特征值目标值】
无监督学习:一般数据构成是【特征值】
Scikit-learn(sklearn)的定位是通用机器学习库&…
Keras使用sklearn中的交叉验证和网格搜索
Keras是Python在深度学习领域非常受欢迎的第三方库,但Keras的侧重点是深度学习,而不是所以的机器学习。事实上,Keras力求极简主义,只专注于快速、简单地定义和构建深度学习模型所需要的内容。Python中的scikit-learn是非常受欢迎的…

ModaHub魔搭社区:自动化机器学习Auto-Sklearn的贝叶斯优化
贝叶斯优化
贝叶斯优化的原理是利用现有的样本在优化目标函数中的表现,构建一个后验模型。该后验模型上的每一个点都是一个高斯分布,即有均值和方差。若该点是已有样本点,则均值就是该点的优化目标函数取值,方差为0。
而其他未知样本点的均值和方差是后验概率拟合的,不…

sklearn数据集API介绍
数据集介绍 sklearn获取数据返回的格式
例:
鸢尾花数据集
from sklearn.datasets import load_iris# 鸢尾花数据集做分类
li load_iris()
# 获取特征值
print(li.data)
# 获取目标值
print(li.target)
# 打印数据集描述
print(li.DESCR) 目标值是离散值…
随机森林 {Keras 由浅入深}
随机森林
TensorFlowKerassklearn
python & mathematics 随机森林是集成学习中的一种方法。 随机森林采用的方法为bagging(样本不放回) from sklearn.ensemble import RandomForestClassifier可参考链接: https://www.cnblogs.com/zongf…
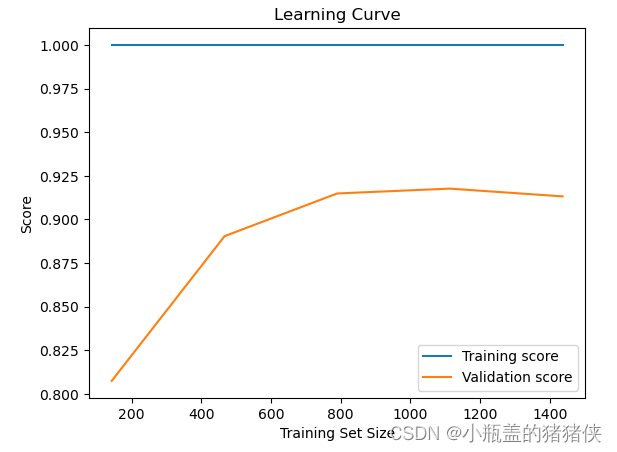
sklearn.model_selection模块介绍
数据集划分方法
train_test_split
train_test_split(*arrays, test_sizeNone, train_sizeNone, random_stateNone, shuffleTrue, stratifyNone)参数包括:
test_size:可选参数,表示测试集的大小。可以是一个表示比例的浮点数(例…
使用sklearn生成TF-IDF词向量
写一个使用sklearn生成TF-IDF词向量的模板函数:
from sklearn import feature_extraction # 导入sklearn库, 以获取文本的tf-idf值
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizerde…
sklearn快速实现python机器学习算法
sklearn又写作scikit-learn基于python的高效机器学习算法应用,开源机器学习工具包官网,里面有全英的教程和示例工程应用中,自己使用python从头实现一个算法耗时耗力,还难以保证架构清晰、稳定性强基本流程:实例化、fit…
(完全解决)如何输入一个图的邻接矩阵(每两个点的亲密度矩阵affinity),然后使用sklearn进行谱聚类
文章目录 背景输入点直接输入邻接矩阵 背景
网上倒是有一些关于使用sklearn进行谱聚类的教程,但是这些教程的输入都是一些点的集合,然后根据谱聚类的原理,其会每两个点计算一次亲密度(可以认为两个点距离越大,亲密度越…
【已解决】ModuleNotFoundError: No module named ‘sklearn‘
问题描述 Traceback (most recent call last): File "/home/visionx/nickle/temp/SimCLR/linear_evaluation.py", line 210, in <module> from sklearn.manifold import TSNE ModuleNotFoundError: No module named sklearn 解决办法
pip install numpy…
LinearSVC与SVC的区别
LinearSVC
基于liblinear库实现 有多种惩罚参数和损失函数可供选择 训练集实例数量大(大于1万)时也可以很好地进行归一化 既支持稠密输入矩阵也支持稀疏输入矩阵 多分类问题采用one-vs-rest方法实现
SVC
基于libsvm库实现 训练时间复杂度为 o(n2)o(n^…

scikit-learn 中决策树模型-参数说明、注解
目录scikit-learn 中决策树算法类库介绍重要参数criterion 特征选择标准对于分类决策树:关于基尼指数对于回归决策树以 squared_error 为例splitter 特征划分点选择标准max_depth 最大深度max_features 划分时考虑的最大特征数min_samples_split 叶子节点允许拆分的…

Scikit-learn学习笔记(一)
Scikit-learn学习笔记(一) 这段时间在学习机器学习相关的知识,一方面要学习理论知识,另一方面还要不断的练习和实践,只有不断的实践才能真正地掌握和理解这些理论知识。在众多编程语言中,python具有独特的优…
如何基于OpenCV和Sklearn库开展数据降维
大家在做数据分析或者机器学习应用过程中,不可避免的需要对数据进行降维操作,好多垂直行业业务中经常出现数据量少但维度巨大的情况。数据降维的目的是为了剔除不相关或冗余特征,使得数据易用,去除无用数据,实现数据可…
scikit-learn : 线性回归
# 线性回归背景 从线性回归(Linear regression)开始学习回归分析,线性回归是最早的也是最基本的模型——把数据拟合成一条直线。 — # 数据集 使用scikit-learn里的数据集boston,boston数据集很适合用来演示线性回归。boston数据集包含了波士顿地区的房屋价格中位数…
sklearn.preprocessing 特征编码汇总
文章目录 常见特征种类one-hot编码特征哈希(`Feature hashing`)基于统计的类别编码对循环特征的编码目标编码(Target encoding)K折目标编码(K-Fold Target encoding)用于数据分析的特征可能有多种形式,需要将其合理转化成模型能够处理的形式,特别是对非数值的特征,特征…
sklearnex | scikit-learn-intelex
ModuleNotFoundError: No module named sklearnex
1.介绍
这是一个面向 Scikit-learn 的英特尔扩展包,是加速 Scikit-learn 应用的无缝方式
官方doc:scikit-learn-intelex PyPI
github
2.安装
pip install scikit-learn-intelex
co…
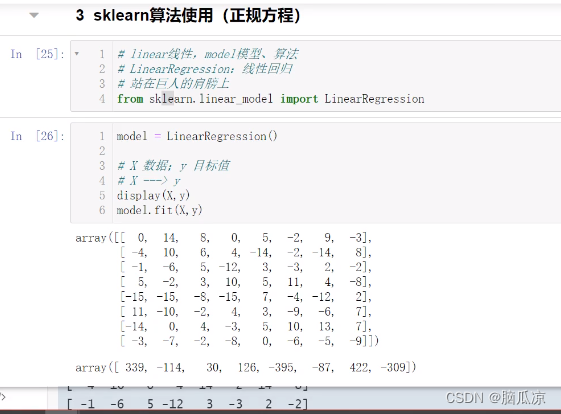
人工智能基础_机器学习003_有监督机器学习_sklearn中线性方程和正规方程的计算_使用sklearn解算八元一次方程---人工智能工作笔记0042
然后我们再来看看,如何使用sklearn,来进行正规方程的运算,当然这里
首先要安装sklearn,这里如何安装sklearn就不说了,自己查一下 首先我们还是来计算前面的八元一次方程的解,但是这次我们不用np.linalg.solve这个
解线性方程的方式,也不用 直接 解正规方程的方式: 也就是上面…
sklearn学习-朴素贝叶斯(二)
文章目录一、概率类模型的评估指标1、布里尔分数Brier Score对数似然函数Log Loss二、calibration_curve:校准可靠性曲线三、多项式朴素贝叶斯以及其变化四、伯努利朴素贝叶斯五、改进多项式朴素贝叶斯:补集朴素贝叶斯ComplementNB六、文本分类案例TF-ID…

python 对图像进行聚类分析
import cv2
import numpy as np
from sklearn.cluster import KMeans
import time# 中文路径读取
def cv_imread(filePath, cv2_falgcv2.COLOR_BGR2RGB): cv_img cv2.imdecode(np.fromfile(filePath, dtypenp.uint8), cv2_falg) return cv_img# 自定义装饰器计算时间
def…
机器学习/sklearn 笔记:K-means,kmeans++,MiniBatchKMeans,二分Kmeans
1 K-means介绍
1.0 方法介绍
KMeans算法通过尝试将样本分成n个方差相等的组来聚类,该算法要求指定群集的数量。它适用于大量样本,并已在许多不同领域的广泛应用领域中使用。KMeans算法将一组样本分成不相交的簇,每个簇由簇中样本的平均值描…
sklearn系列——目录
监督学习 广义线性模型 普通最小二乘法岭回归Lasso回归多任务Lasso弹性网络多任务弹性网络最小角回归坐标下降法正交匹配追踪法贝叶斯回归 贝叶斯岭回归主动相关决策理论 逻辑回归随机梯度下降感知器被动攻击算法稳健回归多项式回归 线性和二次判别分析 线性判别分析二次判别分…
【sklearn】交叉验证 KFold/StratifiedKFold/GroupKFold
KFold/StratifiedKFold/GroupKFold1. sklearn.model_selection.KFold1.1 KFold().split(x) 循环获取分割数据1.2 cross_validate(cvKFold()) 作为cv参数2. sklearn.model_selection.StratifiedKFold3. sklearn.model_selection.GroupKFold1. sklearn.model_selection.KFold
1.…

机器学习算法---时间序列
类别内容导航机器学习机器学习算法应用场景与评价指标机器学习算法—分类机器学习算法—回归机器学习算法—聚类机器学习算法—异常检测机器学习算法—时间序列数据可视化数据可视化—折线图数据可视化—箱线图数据可视化—柱状图数据可视化—饼图、环形图、雷达图统计学检验箱…
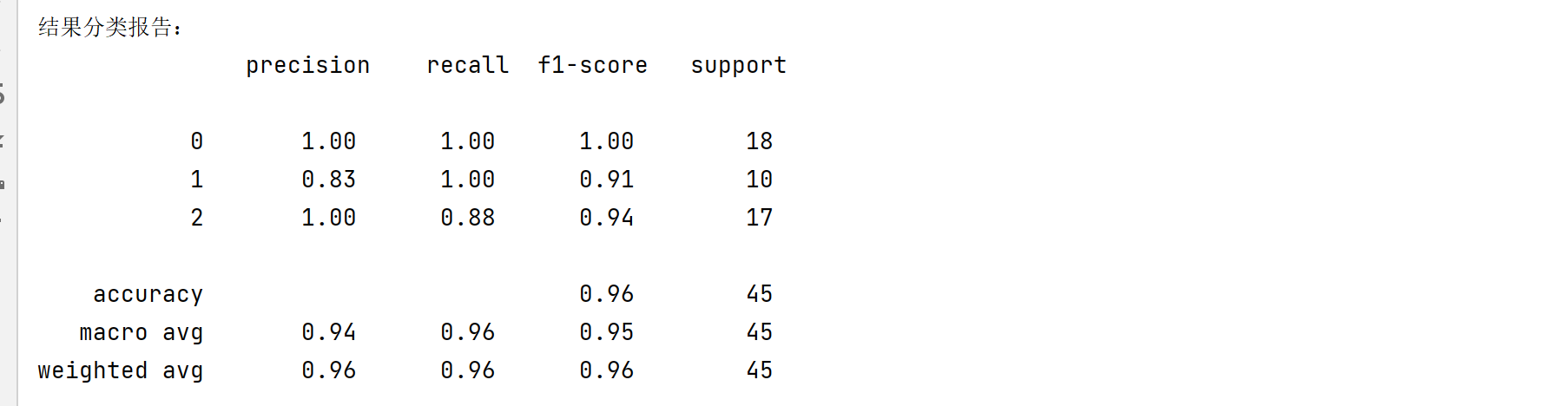
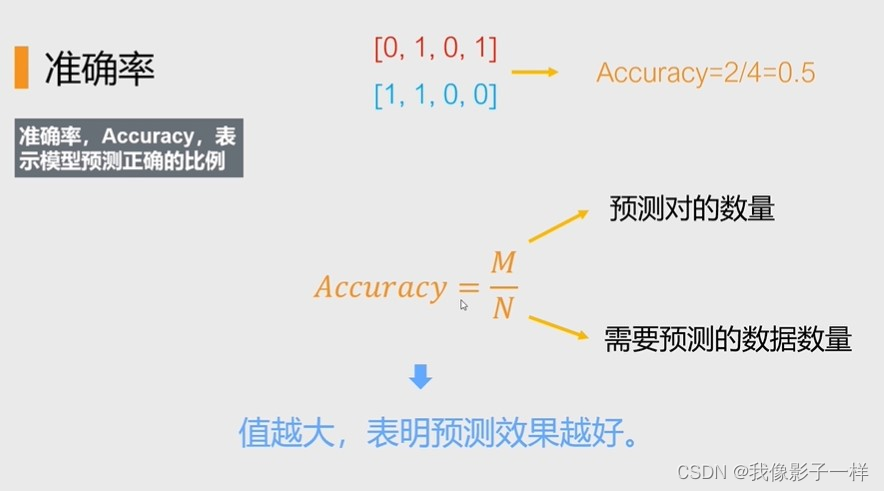
【教学】图像分类算法中的召回率recall、精准率precision和f1score得分等计算。
首先我们来介绍一下这些名称的含义。 TP: 预测为1(Positive),实际也为1(Truth-预测对了)TN: 预测为0(Negative),实际也为0(Truth-预测对了)FP: 预测为1(Positive),实际为0(False-预测错了)FN: 预测为0(Negative),实际为1(False-预测错了)Accuracy = (预测正确的样本数)/(总…
鸢尾花种类预测—流程实现
1. 再识K-近邻算法API
sklearn.neighbors.KNeighborsClassifier(n_neighbors5,algorithm‘auto’)
n_neighbors: int,可选(默认 5),k_neighbors查询默认使⽤的邻居数 algorithm:{‘auto’,‘ball_tree’&…

预测facebook签到位置
1 项⽬描述 本次⽐赛的⽬的是预测⼀个⼈将要签到的地⽅。 为了本次⽐赛,Facebook创建了⼀个虚拟世界,其中包括10公⾥*10 公⾥共100平⽅公⾥的约10万个地⽅。 对于给定的坐标集,您的任务将根据⽤户的位置,准确性和时间戳等预测⽤户…
使用sklearn简单进行SVM参数优选
SVM简单回顾
支持向量机(SVM)方法建立在统计学VC维和结构风险最小化原则上,试图寻找到一个具有最大分类间隔的超平面,支持向量(Support Vector)是支持向量机训练的结果,在进行分类或者回归时也…

使用sklearn.linear_model.SGDClassifier增量模型进行学习的记录
数据集下载链接是Human Activity Recognition Using Smartphones train、test文件夹中分别包含训练和测试的文件,这里使用train中的数据进行增量学习模型,test中的数据用来测试 首先读取数据:
import numpy as np
from sklearn.linear_mode…
随机森林的重要参数、接口及其使用
随机森林的重要参数、接口及其使用
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split,cross_val_score
import matplot…
sklearn与XGBoost
1 在学习XGBoost之前
1.1 xgboost库与XGB的sklearn API
陈天奇创造了XGBoost算法后,很快和一群机器学习爱好者建立了专门调用XGBoost库,名为xgboost。xgboost是一个独立的、开源的,并且专门提供梯度提升树以及XGBoost算法应用的算法库。它和…

机器学习---特征工程介绍
为什么需要特征工程(Feature Engineering)
机器学习领域的大神Andrew Ng(吴恩达)老师说“Coming up with features is difficult, time-consuming, requires expert knowledge. “Applied machine learning” is basically feature engineering. ”
什么是特征工程
特征工程…

ModaHub魔搭社区:自动化机器学习神器Auto-Sklearn
Auto-Sklearn
Auto-Sklearn是一个开源库,用于在 Python 中执行 AutoML。它利用流行的 Scikit-Learn 机器学习库进行数据转换和机器学习算法。
它是由Matthias Feurer等人开发的。并在他们 2015 年题为“efficient and robust automated machine learning 高效且稳健的自动…
sklearn调包解决FutureWarning:1978行报错
Python 解决FutureWarning: warnings.warn(CV_WARNING, FutureWarning)的方法
C:\python3.7.3\lib\site-packages\sklearn\model_selection\_split.py:1978: FutureWarning: The default value of cv will change from 3 to 5 in version 0.22. Specify it explicitly to sile…

【办公类-18-03】(Python)教师研讨表批量制作(学校、姓名、回答1-3)
背景需求: 领导发给我一个word版本的“研讨表”: “随便你做成什么样子,最后能有个二维码给老师们填写反馈就可以了” 我看了看内容,这和我以前做的“闵行区教师信息技术2.0培训作业”完全相同
“OK,我用问卷星收集教…
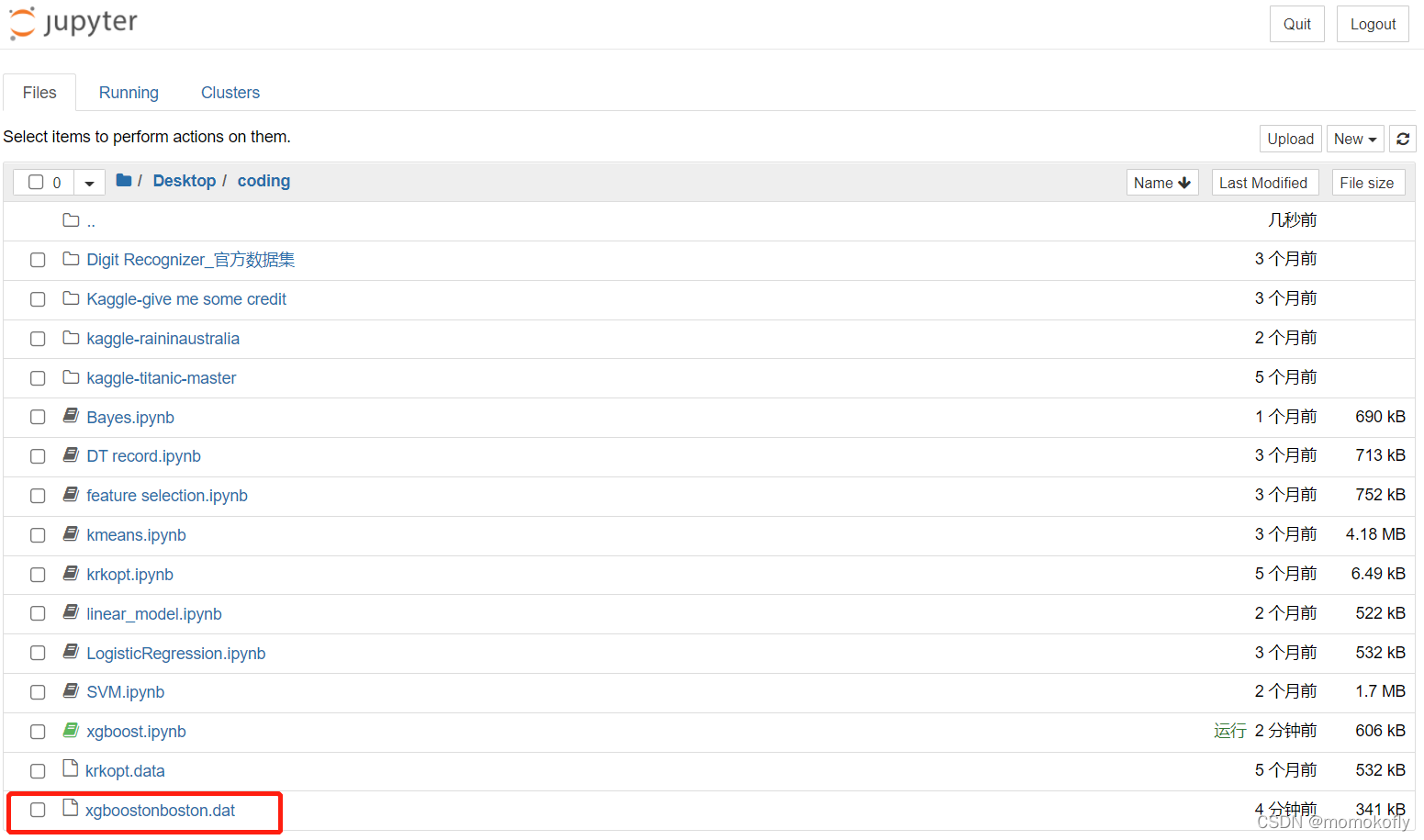
【python】对癌症数据进行特征工程,提升lr模型的准确率(特征工程及模型聚合)
对癌症数据进行特征工程,提升lr模型的准确率1、加载数据2、缺失值处理3、方差过滤4、皮尔斯相关系数分析5、完整代码头文件:import pandas as pd
# 众数
from sklearn.datasets import load_breast_cancer
from sklearn.feature_selection import Varian…
一文学会sklearn中的交叉验证方法,cross_validate和KFlod实战案例
前言
在机器学习中,我们经常需要评估模型的性能。而为了准确评估模型的性能,我们需要使用一种有效的评估方法。五折交叉验证(5-fold cross-validation)就是其中一种常用的模型评估方法,用于评估机器学习模型的性能和泛…
sklearn.feature_selection.SelectFromModel利用模型筛选特征
sklearn.feature_selection.SelectFromModel模型筛选特征
以随机森林为例,查看随机森林之类的模型使用的特征。有两种使用方式:
1, 使用未训练的模型
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble impor…
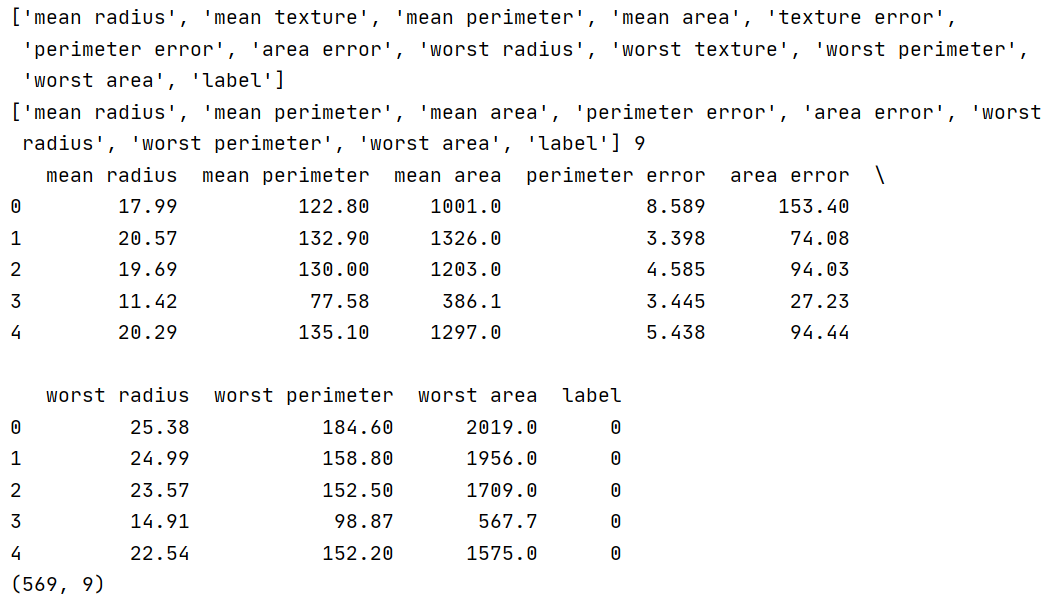
sklearn中make_blobs方法:聚类数据生成器
sklearn中make_blobs()方法参数: n_samples:表示数据样本点个数,默认值100 n_features:是每个样本的特征(或属性)数,也表示数据的维度,默认值是2。默认为 2 维数据,测试选取 2 维数据也方便进行可视化展示…
传统机器学习数据预处理:sklearn.model_selection.train_test_split
sklearn.model_selection.train_test_split(* arrays,** options )[资源]
将数组或矩阵拆分为随机训练和测试子集
快速实用程序,用于包装输入验证和应用程序,以将输入数据打包 到一个调用中,以在oneliner…

sklearn 逻辑回归Demo
逻辑回归案例
假设表示
基于上述情况,要使分类器的输出在[0,1]之间,可以采用假设表示的方法。 设 h θ ( x ) g ( θ T x ) h_θ (x)g(θ^T x) hθ(x)g(θTx), 其中 g ( z ) 1 ( 1 e − z ) g(z)\frac{1}{(1e^{−z} )} g(z)(1e−z)1…
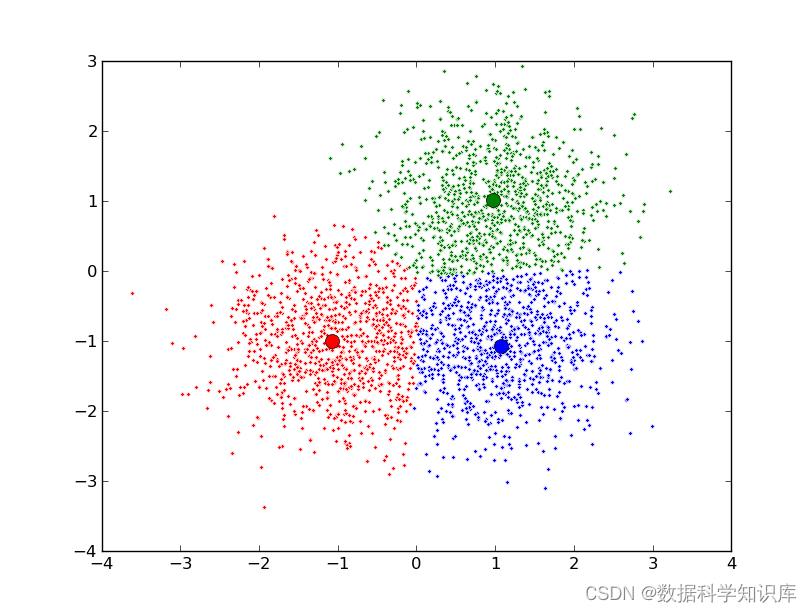
机器学习算法---聚类
类别内容导航机器学习机器学习算法应用场景与评价指标机器学习算法—分类机器学习算法—回归机器学习算法—聚类机器学习算法—异常检测机器学习算法—时间序列数据可视化数据可视化—折线图数据可视化—箱线图数据可视化—柱状图数据可视化—饼图、环形图、雷达图统计学检验箱…

(实战)sklearn----岭回归标准方程法----岭回归
数据集
import numpy as np
from numpy import genfromtxt
from sklearn import linear_model
import matplotlib.pyplot as plt# 读入数据
data genfromtxt(r"longley.csv",delimiter,)
print(data)# 切分数据
x_data data[1:,2:]
y_data data[1:,1]
print(x…
sklearn库学习--SelectKBest 、f_regression
目录 一、SelectKBest 介绍、代码使用
介绍:
代码使用:
二、评分函数
【1】f_regression:
(1)介绍:
(2)F值和相关系数
【2】除了f_regression函数,还有一些适用于…
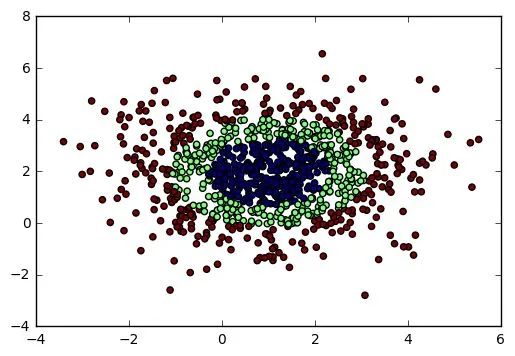
【机器学习】机器学习算法的随机数据生成
文章目录一、前言二、numpy随机数据生成API2.1 rand(d0d_0d0, d1d_1d1, ..., dnd_ndn)2.2 randn((d0d_0d0, d1d_1d1, ..., dnd_ndn)2.3 randint(low[, high, size])2.4 random_integers(low[, high, size])2.5 random_sample([size])三、scikit-learn随机数据生成A…

机器学习基础16-建立预测模型项目模板
机器学习是一项经验技能,经验越多越好。在项目建立的过程中,实 践是掌握机器学习的最佳手段。在实践过程中,通过实际操作加深对分类和回归问题的每一个步骤的理解,达到学习机器学习的目的 预测模型项目模板
不能只通过阅读来掌握…
sklearn Preprocessing 数据预处理功能
scikit-learn(或sklearn)的数据预处理模块提供了一系列用于处理和准备数据的工具。这些工具可以帮助你在将数据输入到机器学习模型之前对其进行预处理、清洗和转换。以下是一些常用的sklearn.preprocessing模块中的类和功能:
1. 数据缩放和中…
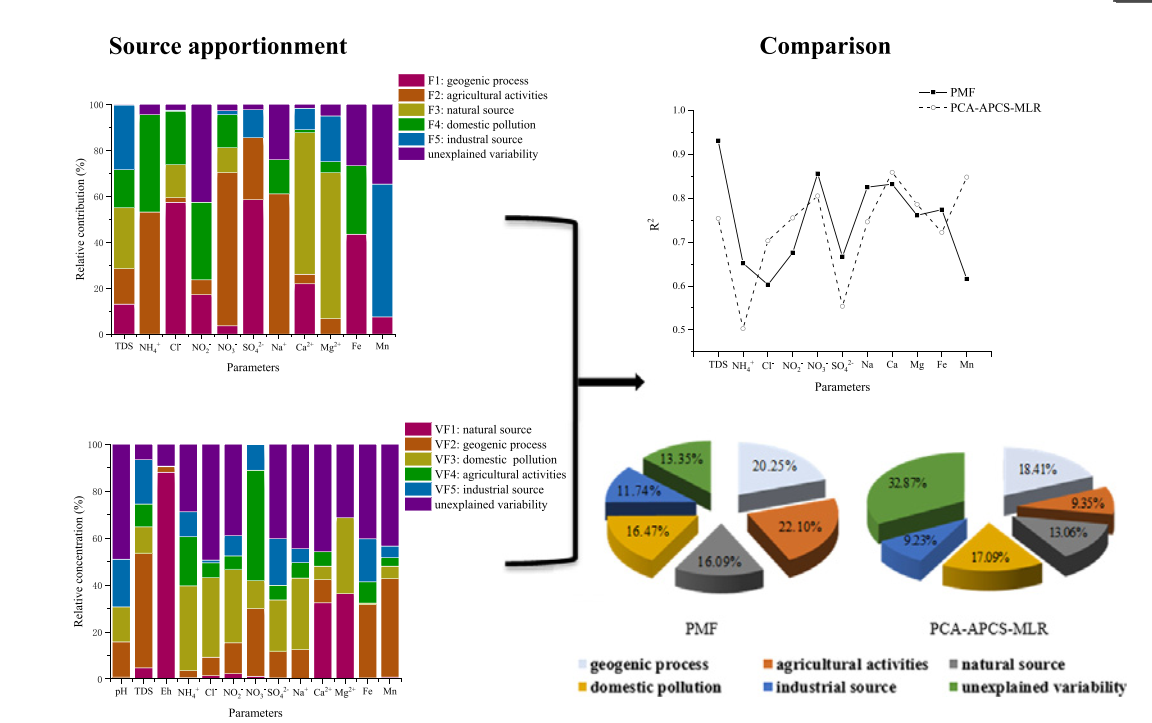
PCA-APCA-MLR
全称
principal component analysis-absolute principal component score-multiple linear regression
原理
绝对因子分析/多元线性回归受体模型(APCS—MLR)的基本原理是将因子分析的主因子得分转化为绝对主因子得分(APCS),各指标含量再分别对所有的APCS进行多元线性回…
sklearn.preprocessing中的标准化StandardScaler与scale的区别
StandardScaler与scale 1、标准化概述2、两种标准化的区别 1、标准化概述 标准化主要用于对样本数据在不同特征维度进行伸缩变换,目的是使得不同度量之间的特征具有可比性,同时不改变原始数据的分布
一些机器学习算法对输入数据的规模和量纲非常敏感&am…
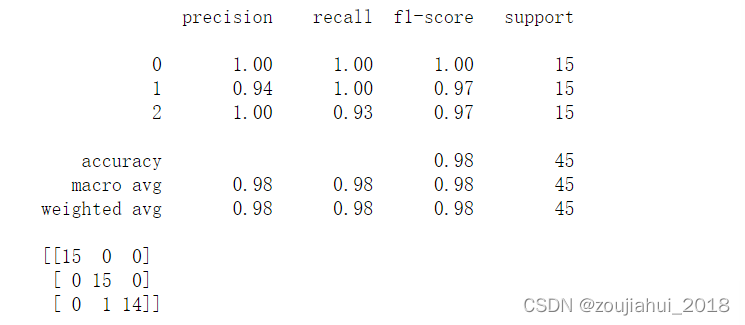
朴素贝叶斯分类的python的实现
文章目录介绍GaussianNB()参数介绍实例BernoulliNB()参数介绍实例MultinomialNB()参数介绍实例作者:王乐介绍
sklearn 是 scikit–learn 的简称,是一个基于 Python 的第三方模块。 sklearn 库集成了一些常用的机器学习方法,在进行机器学习任务时,并不需要实现算法,…
机器学习-决策树算法原理及实现-附python代码
1.决策树-分类树
sklearn.tree.DecisionTreeClassifier官方地址: https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html#sklearn.tree.DecisionTreeClassifier
在机器学习中,决策树是最常用也是最强大的监督学…
【Sklearn】基于线性判别法的数据分类预测(Excel可直接替换数据)
【Sklearn】基于线性判别法的数据分类预测(Excel可直接替换数据) 1.模型原理2.模型参数3.文件结构4.Excel数据5.下载地址6.完整代码7.运行结果1.模型原理
线性判别分析(Linear Discriminant Analysis,简称LDA)是一种经典的模式识别和分类方法,它的目标是找到一个投影,将…
sklearn网格搜索找寻最优参数
大家好,在机器学习中,调参是一个非常重要的步骤,它可以帮助我们找到最优的模型参数,从而提高模型的性能。然而,手动调参是一项繁琐且耗时的工作,因此需要一种自动化的方法来搜索最佳参数组合。在这方面&…

【教学类-40-04】A4骰子纸模制作4.0(4.5CM嵌套+记录表带符号)
作品展示 背景需求
骰子3.0(7字形)存在问题:6.5骰子体积大大,不适合幼儿操作(和幼儿手掌一样大,制作耗时,甩动费力)
1.0版本:边缘折线多,幼儿剪起来费力。 …
sklearn-6算法链与管道
思想类似于pipeline,将多个处理步骤连接起来。
看个例子,如果用MinMaxScaler和训练模型,需要反复执行fit和tranform方法,很繁琐,然后还要网格搜索,交叉验证
1 预处理进行参数选择
对于放缩的数据&#x…
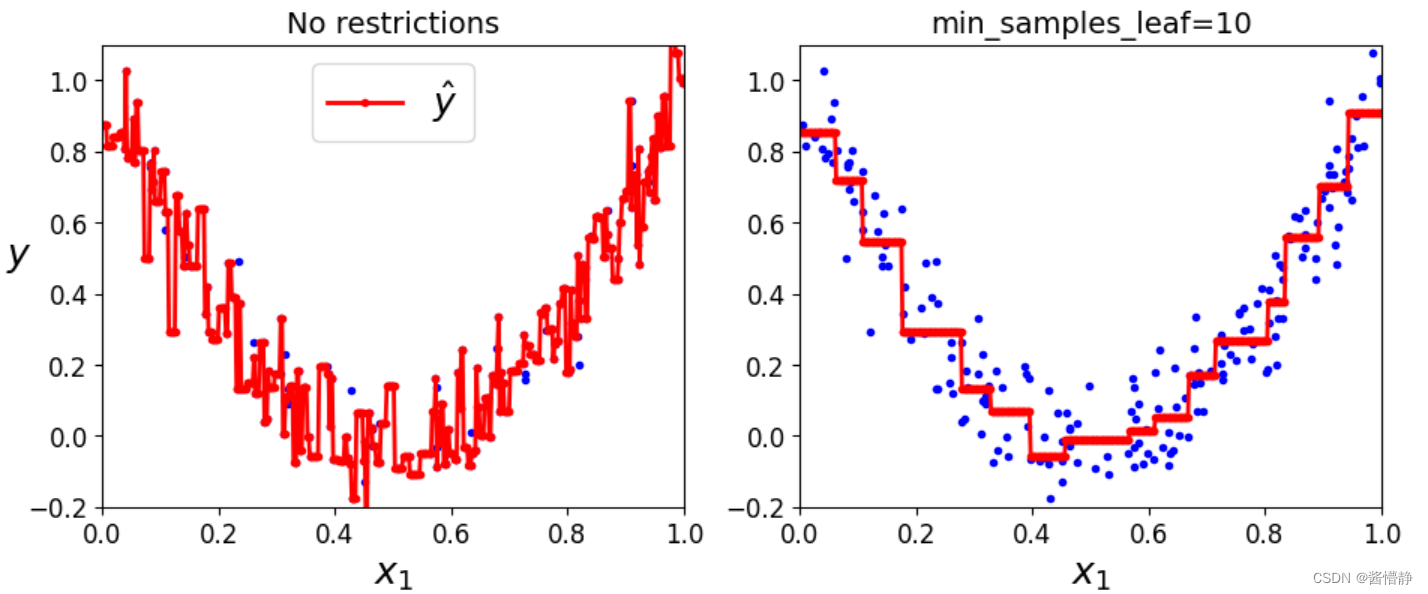
【机器学习】决策树(实战)
决策树(实战) 目录一、准备工作(设置 jupyter notebook 中的字体大小样式等)二、树模型的可视化展示1、通过鸢尾花数据集构建一个决策树模型2、对决策树进行可视化展示的具体步骤3、概率估计三、决策边界展示四、决策树的正则化&a…
Scikit-Learn的评估器API学习-线性分类器
Scikit-Learn的评估器API遵照以下设计原则:
统一性内省限制对象层级函数组合明智的默认值 使用Scikit-Learn评估器API训练模型的常用步骤:
一. 通过从Scikit-Learn中导入适当的模型评估器, 选择模型类
如从线性模型中选择线性回归模型
from sklearn.linear_model import Li…
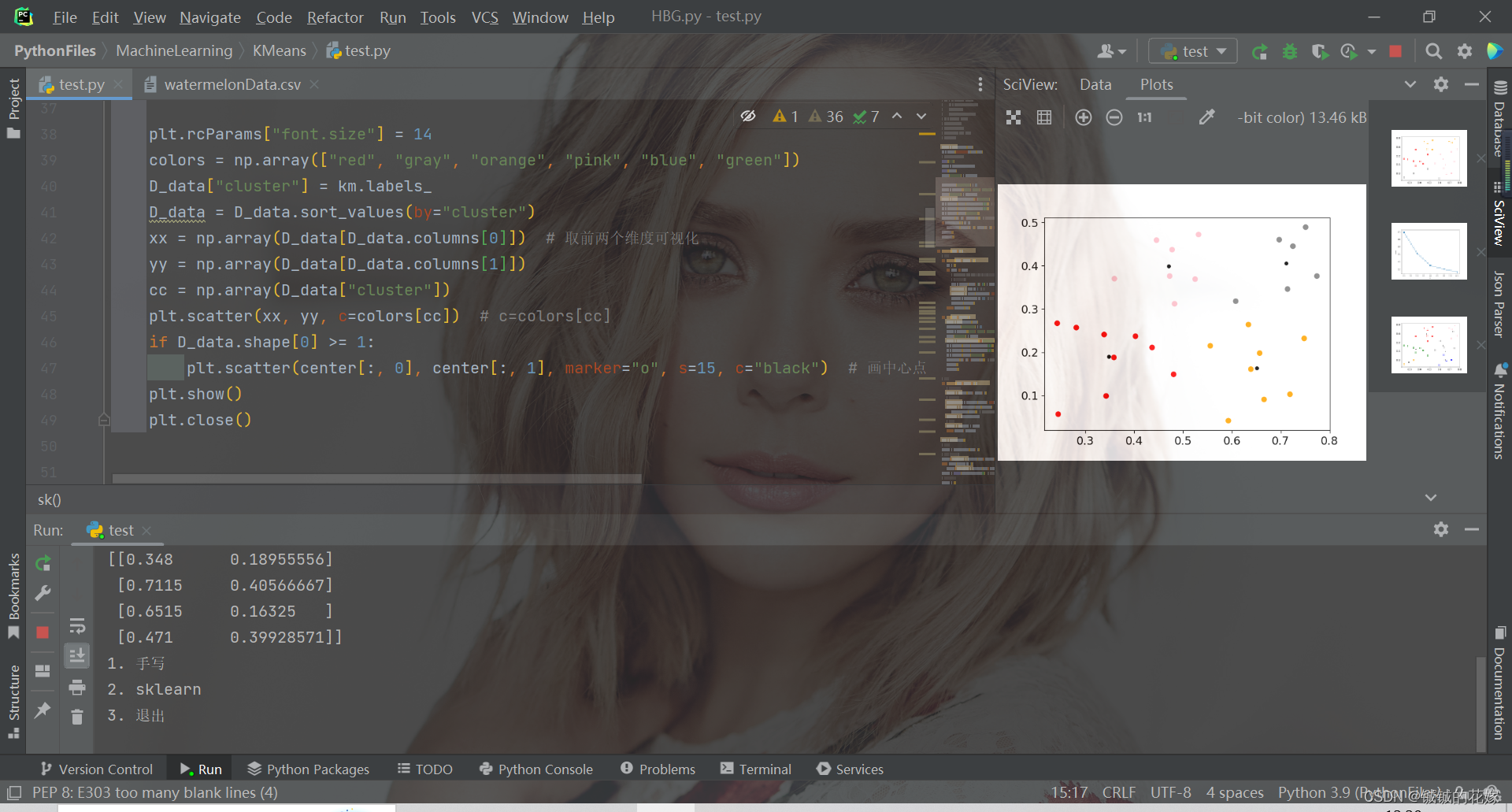
机器学习之K-means原理详解、公式推导、简单实例(python实现,sklearn调包)
目录1. 聚类原理1.1. 无监督与聚类1.2. K均值算法2. 公式推导2.1. 距离2.2. 最小平方误差3. 实例3.1. python实现3.2. sklearn实现4. 运行(可直接食用)1. 聚类原理
1.1. 无监督与聚类
在这部分我今天主要介绍K均值聚类算法,在这之前我想提一…
Sklearn线性回归
Scikit-learn 中的线性回归是一个用于监督学习的算法,它用于拟合数据集中的特征和目标变量之间的线性关系。以下是使用 Scikit-learn 实现线性回归的基本步骤:
1. 导入所需库
首先,你需要导入所需的库和模块。
import numpy as np
import …
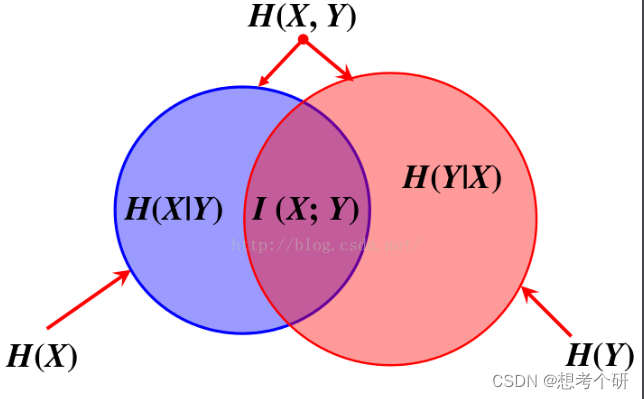
T检验、F检验、卡方检验、互信息法及机器学习应用
1、T检验
目的:主要是为了比较数据样本之间是否具有显著性的差异。主要通过样本均值的差异进行检验,判断差异性。
前置条件:样本服从正态分布;各样本间独立。
适用:小样本(n<30); 定量数据…
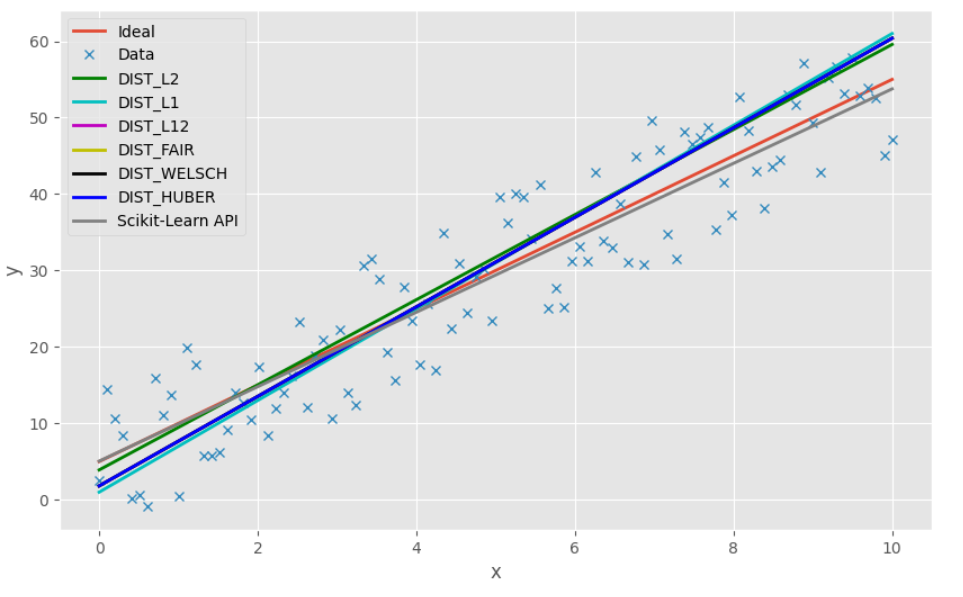
OpenCV与机器学习:使用opencv和sklearn实现线性回归
前言
线性回归是一种统计分析方法,用于确定两种或两种以上变量之间相互依赖的定量关系。在统计学中,线性回归利用线性回归方程(最小二乘函数)对一个或多个自变量(特征值)和因变量(目标值&#…
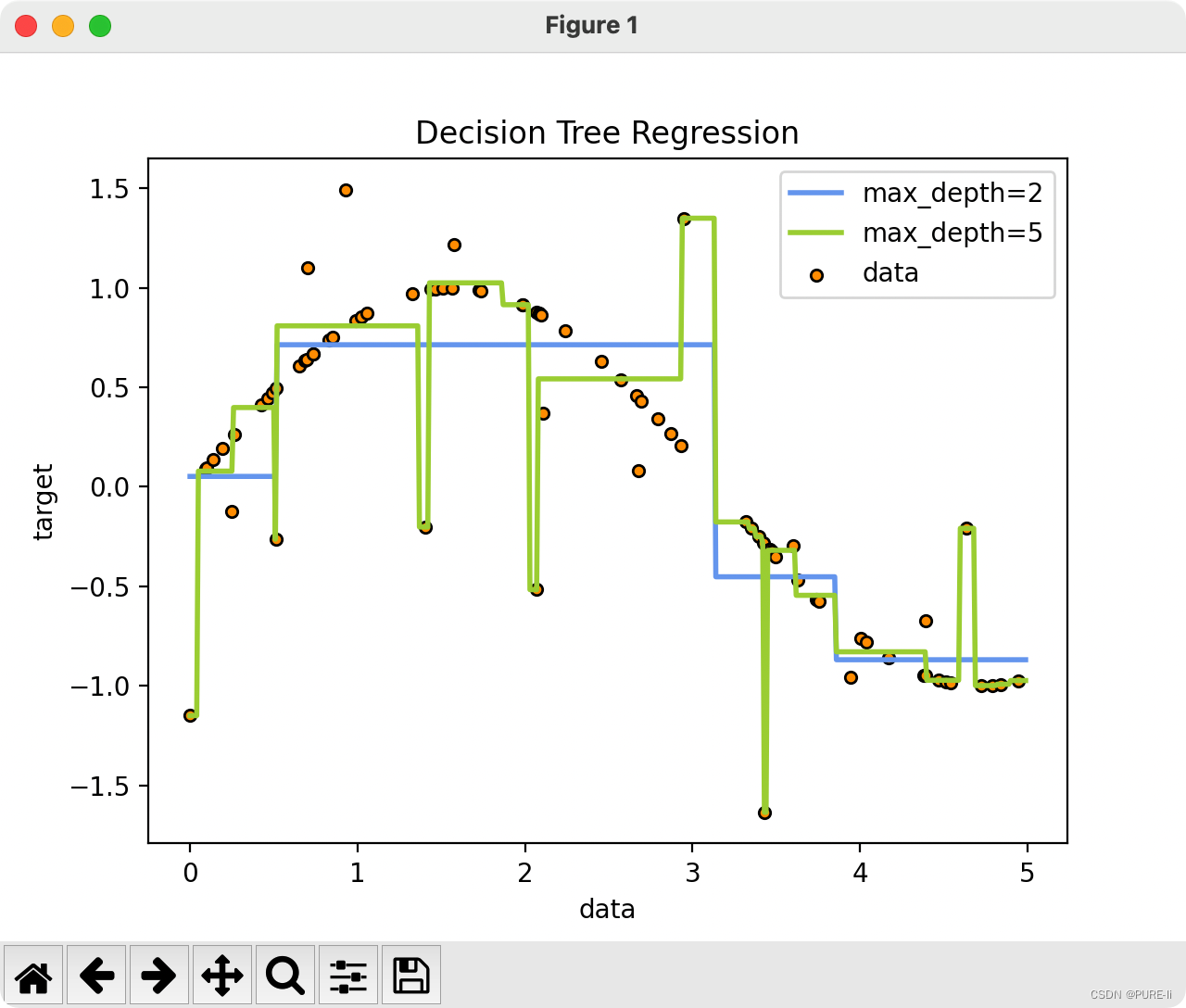
决策树在sklearn中的实现
目录
一.模块sklearn.tree
二.建模基本流程
三.DecisionTreeClassifier重要参数
1.criterion
2.random_state & splitter
3.剪枝参数max_depth
4.剪枝参数min_samples_leaf & min_samples_split
5.max_features & min_impurity_decrease
6.class_weight …

Python实现逻辑回归(Logistic Regression)
💥 项目专栏:【Python实现经典机器学习算法】附代码原理介绍 文章目录 前言一、基于原生Python实现逻辑回归算法二、逻辑回归模型的算法原理三、算法实现3.1 导包3.2 定义随机数种子3.3 定义逻辑回归模型3.3.1 模型训练3.3.1.1 初始化参数3.3.1.2 正向传…
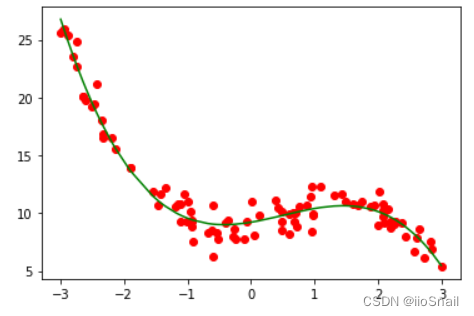
详解使用sklearn实现一元线性回归和多元线性回归
[Open In Colab] 文章目录 1. 线性回归简介2. 使用sklearn进行一元线性回归3. 线性回归的coef_参数和intercept_参数4. 使用sklearn实现多元线性回归4.1 利用PolynomialFeatures构造输入4.2 进行多元线性回归 5. 总结 import numpy as np
import matplotlib.pyplot as plt1. 线…
Python模糊匹配搜索fuzzywuzzy和difflib
文章目录 概述fuzzywuzzyfuzzy模块 difflib 概述
利用python库:fuzzywuzzy及difflib,两个库均可实现词粒度的模糊匹配,同时可设定模糊阈值,实现关键词的提取、地址匹配、语法检查等
fuzzywuzzy pip install fuzzywuzzy from fuz…
sklearn中tfidf的计算与手工计算不同详解
sklearn中tfidf的计算与手工计算不同详解 引言:本周数据仓库与数据挖掘课程布置了word2vec的课程作业,要求是手动计算corpus中各个词的tfidf,并用sklearn验证自己计算的结果。但是博主手动计算的结果无论如何也与sklearn中的结果无法对应&…
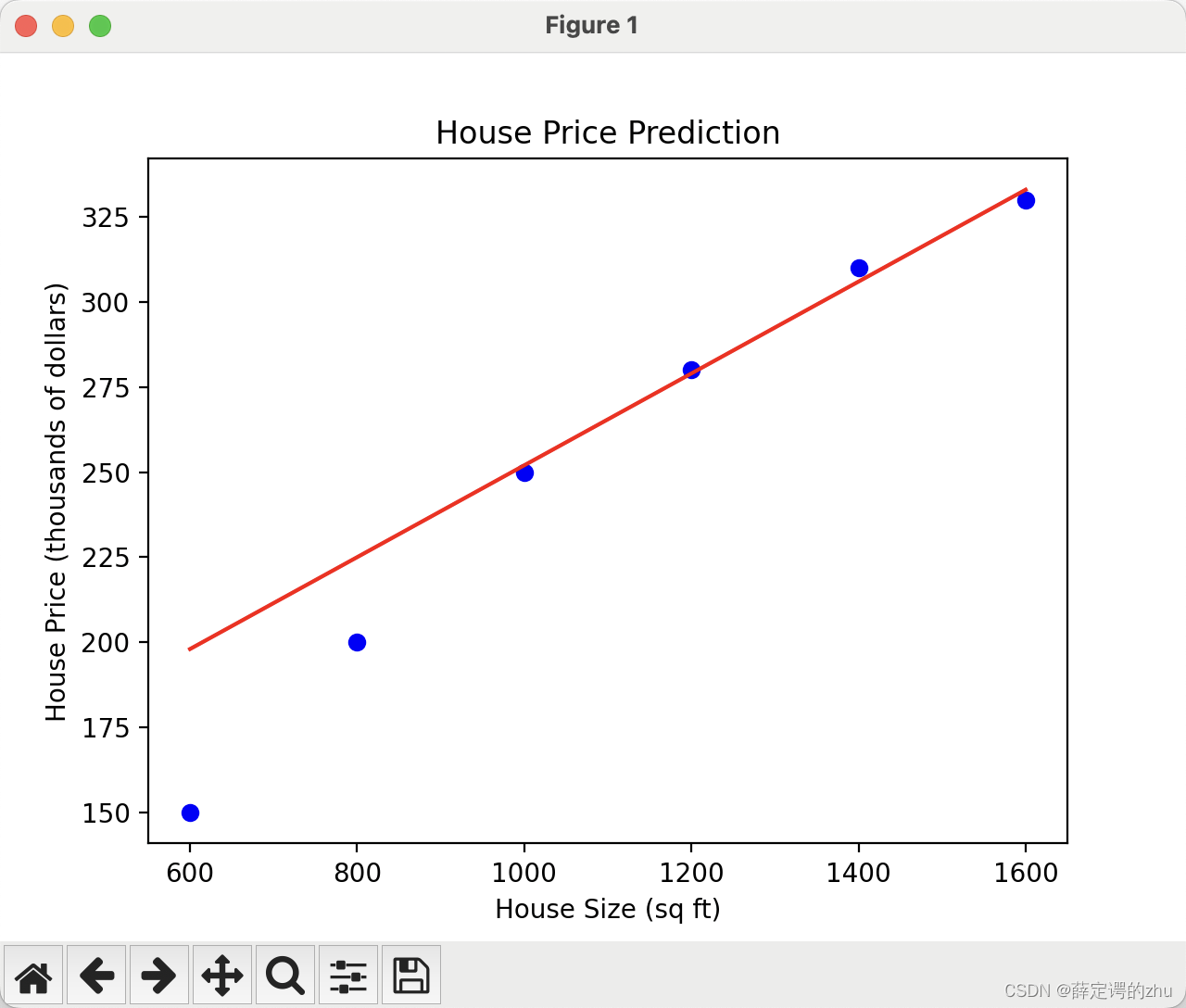
利用numpy+sklearn+matplotlib演示如何创建和训练线性回归模型
通过一个具体的业务场景来演示如何创建和训练线性回归模型。让我们考虑一个房地产市场的例子,其中我们想要根据房屋的大小(平方英尺)来预测其市场价格。
业务场景
假设你的任务是帮助一个房地产公司预测不同大小房屋的市场价格。你有一份包…
![[已解决] 决定系数R2为何为负 from sklearn.metrics import r2_score](https://img-blog.csdnimg.cn/14a86e054d2d4f65bf377e1238b482a1.png)
[已解决] 决定系数R2为何为负 from sklearn.metrics import r2_score
最近在炼丹发现一件很有趣的现象,决定系数R2竟然为负,小学生都知道任何一个常数的平方绝不可能为负,潜意识里告诉我这里面必有蹊跷,因此查阅许多资料得知,决定系数R2不是r相关系数的平方这么简单,实际上当非…
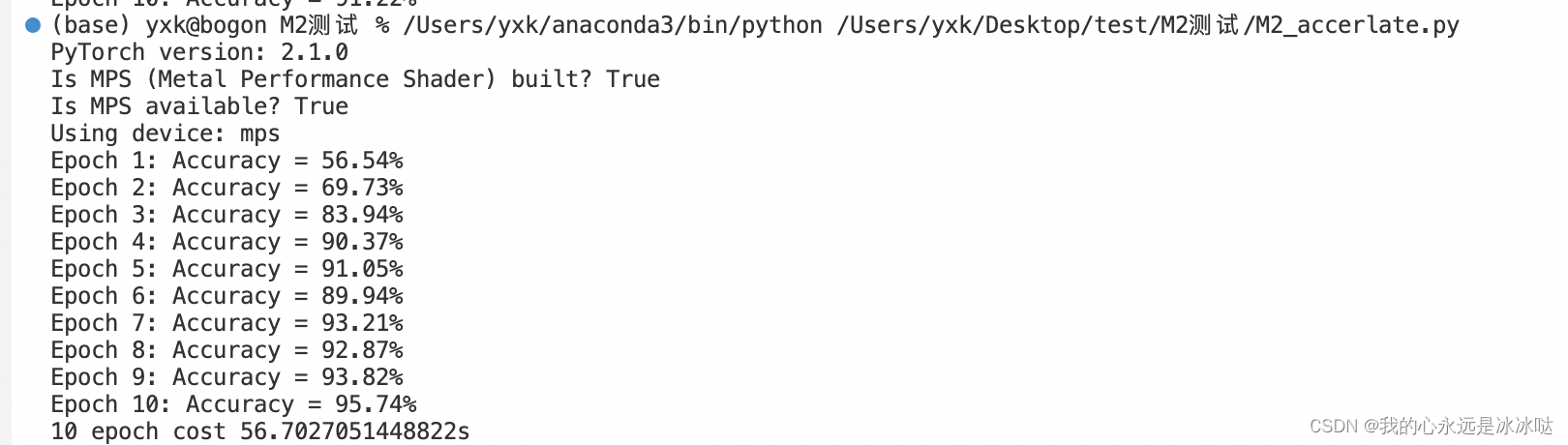
pytoch M2芯片测试
今天才发现我的新片是M2芯片,而不是M1芯片,有点尴尬 参考网址 https://www.oldcai.com/ai/pytorch-train-MNIST-with-gpu-on-mac/
测试结果如下
M2_cpu.py
# https://www.oldcai.com/ai/pytorch-train-MNIST-with-gpu-on-mac/
import torch
from tor…
【sklearn练习】model常用属性和功能
介绍
scikit-learn 中的机器学习模型(estimator)通常具有一组常用属性和功能,这些属性和功能可以用于训练、评估和使用模型。以下是一些常见的模型属性和功能:
常见属性: coef_:对于线性模型(…

Boosting 算法(AdaBoost,sklearn 代码示例,提升树)
文章目录AdaBoost 算法Boosting 的基本思路AdaBoost 算法提升树提升树模型提升树算法梯度提升ReferencesBoosting 是一种常用的机器学习方法,应用广泛且有效。在分类问题中,它通过改变训练样本的权重学习多个弱分类器,由这些弱学习器的预测结…
机器学习框架sklearn之决策树
概念
决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-else结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法。
如何高效的进行决策?
特征的先后顺序
在应用决策树之前,我们先了解一下信息熵和信息增益…

sklearn----弹性网(实战)
弹性网
import numpy as np
from numpy import genfromtxt
from sklearn import linear_model# 读入数据
data genfromtxt(r"longley.csv",delimiter,)
print(data)# 切分数据
x_data data[1:,2:]
y_data data[1:,1]
print(x_data)
print(y_data)# 创建模型
m…
随机森林原理sklearn实现
原理
定义 随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树, 而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。 随机森林的名称中有两个关键词,一个是“随机”&a…
sklearn中的TfidfTransformer和gensim中的TfidfModel的区别
sklearn.feature_extraction.text.TfidfTransformer 和 gensim.models.TfidfModel 都是用于计算文本数据的 TF-IDF 值的工具。它们的主要区别在于实现方式和输入数据的格式。 1、实现方式和输入数据格式:
TfidfTransformer 是 scikit-learn 中的一个类,…
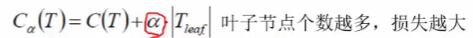
十大经典机器学习算法——决策树
目录
一.什么是决策树
二.构造决策树
三.优缺点 一.什么是决策树
一种最基本的分类与回归方法,因为实际应用中基本上全是用来分类,所以重点讨论分类决策树。其本质就是一颗树,根据损失函数最小化原则选择根节点,节点决定分类的走向哪个叶…
sklearn 学习-混淆矩阵 Confusion matrix
混淆矩阵Confusion matrix:也称为误差矩阵,通过计算得出矩阵的结果用来表示分类器的精度。其每一列代表预测值,每一行代表的是实际的类别。 from sklearn.metrics import confusion_matrixy_true [2, 0, 2, 2, 0, 1]
y_pred [0, 0, 2, 2, 0…

【Sklearn】基于支持向量机算法的数据分类预测(Excel可直接替换数据)
【Sklearn】基于支持向量机算法的数据分类预测(Excel可直接替换数据) 1.模型原理1.1 数学模型1.2 模型原理 2.模型参数3.文件结构4.Excel数据5.下载地址6.完整代码7.运行结果 1.模型原理
支持向量机(Support Vector Machine,SVM&…

【Sklearn】基于逻辑回归算法的数据分类预测(Excel可直接替换数据))
【Sklearn】基于逻辑回归算法的数据分类预测(Excel可直接替换数据) 1.模型原理2.模型参数3.文件结构4.Excel数据5.下载地址6.完整代码7.运行结果 1.模型原理
逻辑回归是一种用于二分类问题的统计学习方法,尽管名字中含有“回归”,…
【Sklearn】基于AdaBoost算法的数据分类预测(Excel可直接替换数据)
【Sklearn】基于AdaBoost算法的数据分类预测(Excel可直接替换数据) 1.模型原理2.模型参数3.文件结构4.Excel数据5.下载地址6.完整代码7.运行结果1.模型原理
AdaBoost(Adaptive Boosting)是一种集成学习算法,它通过组合多个弱分类器来构建一个更强大的分类器。下面是AdaBo…
Python--Sklearn库函数文档API
以下是 sklearn 官方文档中文版 scikit-learn 0.18 中文文档 快速入门用户指南 监督学习 Generalized Linear Models ( 广义线性模型 )Linear and Quadratic Discriminant Analysis ( 线性和二次判别分析 )Kernel ridge regression ( 内核岭回归 )Support Vector Machines&am…

机器学习入门-----sklearn
机器学习基础了解
概念
机器学习是人工智能的一个实现途径 深度学习是机器学习的一个方法发展而来 定义:从数据中自动分析获得模型,并利用模型对特征数据【数据集:特征值+目标值构成】进行预测
算法
数据集的目标值是类别的话叫做分类问题;目标值是连续的数值的话叫做回…
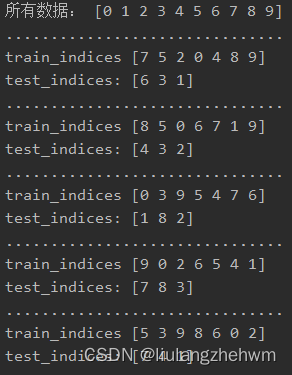
Python机器学习019:sklearn中如何找到测试集中预测错误的样本在原数据中所在的索引位置
原理
要查看预测错误的 X_test 在原始数据集中的索引,你可以首先找到预测错误的样本索引,然后将这些索引映射回原始数据集的索引。
案例
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metric…
sklearn.utils.shuffle 用法小技巧
是可以打乱多组数据的,不局限与x,y。
import numpy as np
import random
from sklearn.utils import shufflea np.array([1,2,3,4,5])
b np.array([0.1,0.2,0.3,0.4,0.5])
c np.array([-1,-2,-3,-4,-5])a,b,c shuffle(a,b,c)
print(a)
print(b)
pri…
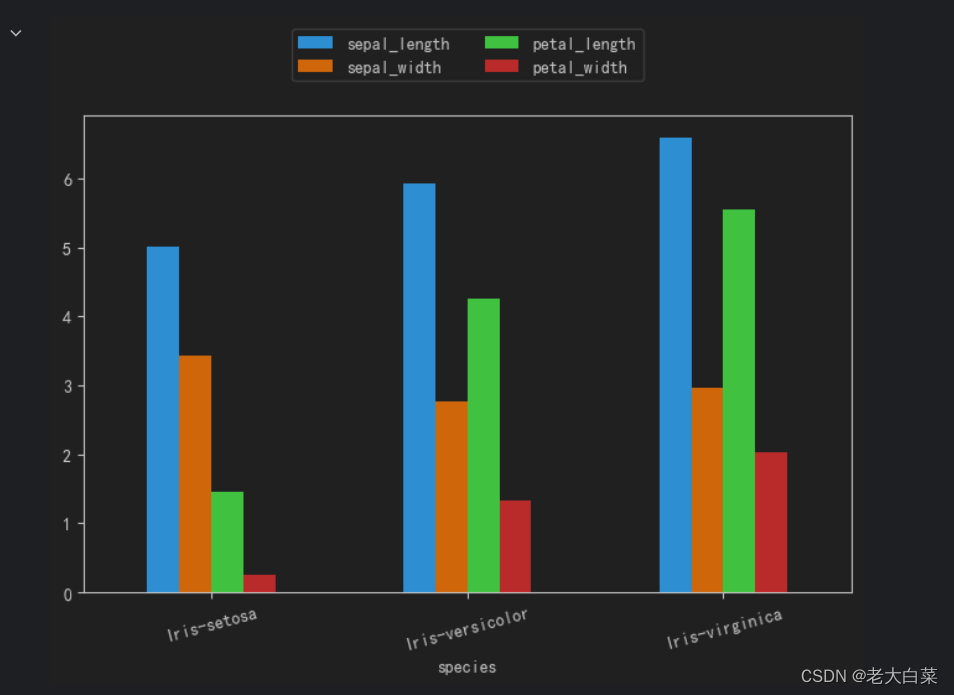
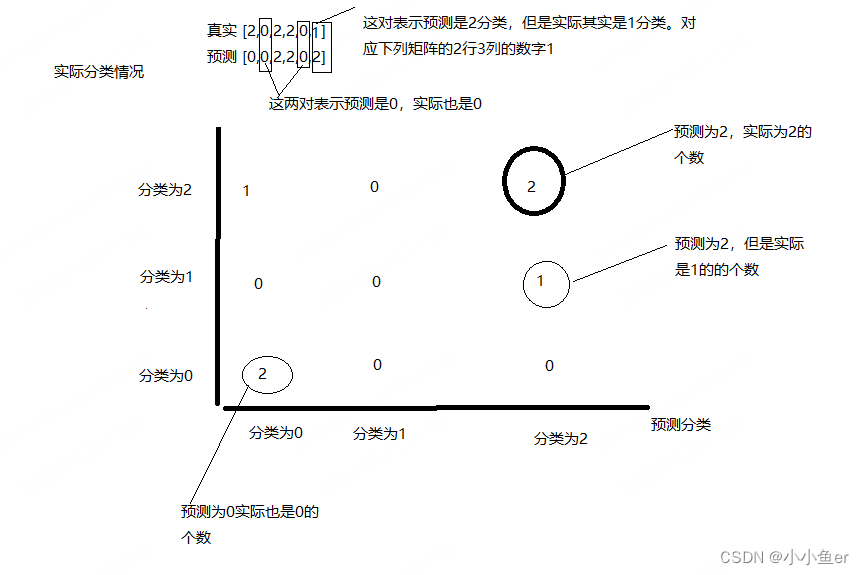
sklearn学习之用matplotlib绘制鸢尾花(Iris)数据集的两个特征:花萼的长度和宽度
直接上代码
sklearn Iris 数据集是机器学习和数据科学中经常使用的一个标准数据集,用于分类任务
from sklearn import datasets # 加载 Iris 数据集
iris datasets.load_iris() # 查看数据集中的特征名称
print("特征名称:", iris.feature_names…
Python-sklearn-diabetes项目实战
目录
1 下载数据集和预处理
1.1 加载/下载数据集
1.2 数据可视化
1.3 数据清洗
1.4 特征工程
1.5 构建特征集和标签集
1.6 拆分训练集和测试集
2 训练模型
2.1 选择算法和确定模型
2.2 训练拟合模型
3 评估并优化模型性能 本文以糖尿病数据集diabetes为基础进行线性…
sklearn.preprocessing中scale和standardscaler
区别:正态分布的平均数为μ,标准差为σ;不同的正态分布可能有不同的μ值和σ值,正态分布曲线形态因此不同。 标准正态分布平均数μ0,标准差σ1,μ和σ都是固定值;标准正态分布曲线形态固定。&am…
机器学习之特征工程(2)特征预处理
特征预处理
将特征数据转化为更加适合算法模型的特征数据的过程。
内容:
归一化标准化
API sklearn.preprocessing
归一化
将数值映射到区间[0,1] 缺点 鲁棒性较差,容易受异常值的影响,只适合传统的精确小数据场景 计算公式 x′x−mi…
sklearn 机器学习基本用法
# # 科学计算模块
# import numpy as np
# import pandas as pd
# # 绘图模块
# import matplotlib as mpl
# import matplotlib.pyplot as plt
# from sklearn.linear_model import LinearRegression
# from sklearn import datasets
# from sklearn.model_selection import t…
头歌---数据挖掘算法原理与实践:数据预处理
第1关:标准化
为什么要进行标准化
对于大多数数据挖掘算法来说,数据集的标准化是基本要求。这是因为,如果特征不服从或者近似服从标准正态分布(即,零均值、单位标准差的正态分布)的话,算法的表…
ModuleNotFoundError: No module named ‘sklearn.cross_validation‘
一、问题分析
ModuleNotFoundError: No module named sklearn.cross_validation
英文先翻译一遍,模块未找到问题,这里涉及到sklearn这个模块,Sklearn (全称 SciKit-Learn),是基于 Python 语言的机器学习工…
Python+neo4j构建豆瓣电影知识图谱
文章目录 数据来源数据整理导入节点和关系导入使用Subgraph批量导入节点和关系 多标签实体和实体去重 数据来源
http://www.openkg.cn/dataset/douban-movie-kg 该网址拥有丰富的中文知识图谱数据集,OpenKG(Open Knowledge Graph),可供研究人员使用研究…

逻辑回归以及sklearn.linear_model.LogisticRegression的使用
一、逻辑回归
1、基本概念 (1)分类算法:通过对训练样本进行学习,得到从样本特征到标签之间的映射关系,也就是假设函数,然后通过该假设函数对新数据进行分类。 (2)广义线性模型…
xgb和gbm做回归代码sklearn
xgb和gbm做回归代码sklearn接口
import numpy as np
import pandas as pd
import re
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_splitfrom sklearn import datasets
from sklearn.model_selection imp…
一文带你搞懂sklearn.metrics混淆矩阵
一般的二分类任务需要的评价指标有4个
accuracyprecisionrecallf1-score
四个指标的计算公式如下 计算这些指标要涉及到下面这四个概念,而它们又构成了混淆矩阵
TP (True Positive)FP (False Positive)TN (True Negative)FN (False Negative)
混淆矩阵实际值01预测…
pandas使用技巧 实用技巧
目录 1 去重、按照某几列去重 drop_duplicates 2 创建dataframe
3 DataFrame定位数据
4 pandas过滤数据query
在调用preprocessing依赖时发现的问题 || 使用keras和sklearn做类别标签转换
文章目录1 问题描述2 总结1 问题描述
在导入preprocessing时,发现有一个地方非常容易出错。
from sklearn import preprocessing
区别于
from keras import preprocessing2 总结 > sklearn会更好用!参考博文 https://blog.csdn.net/qq_40947610/art…
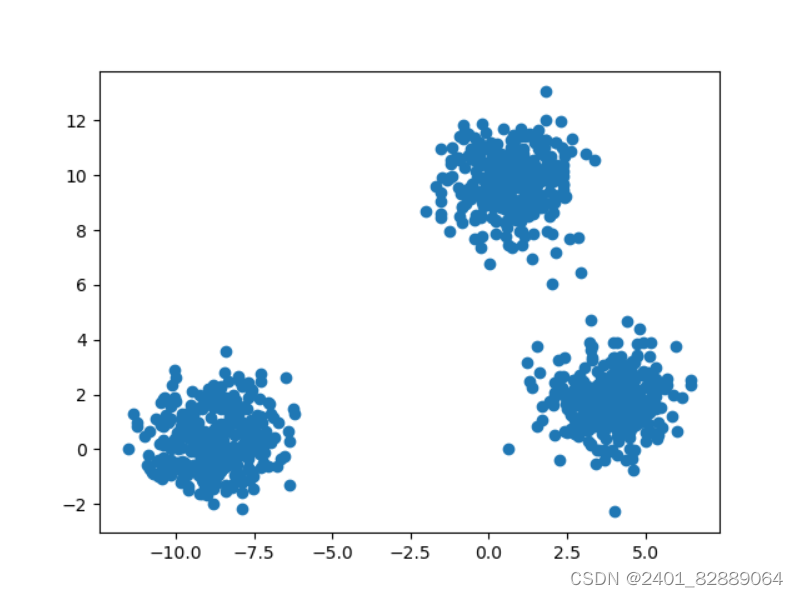
Python-sklearn.datasets-make_blobs
sklearn.datasets.make_blobs()函数形参详解
"""
Title: datasets for regression
Time: 2024/3/5
Author: Michael Jie
"""from sklearn import datasets
import matplotlib.pyplot as plt# 产生服从正态分布的聚类数据
x, y, cen…
Sklearn特征提取
模块 sklearn.feature_extraction 可用于提取符合机器学习算法支持的特征,比如文本和图片。
注意 特征特征提取与特征选择有很大的不同:前者包括将任意数据(如文本或图像)转换为可用于机器学习的数值特征。后者是将这些特征应用到…
机器学习的一些基本知识点
一、什么是机器学习 机器学习是一门能够发觉数据价值的算法与应用,通过自学习算法的开发,从数据中获取知识, 进而实现对未知事件的预测.它提供了一种从数据中获取知识的方法,同时能够逐步提高预测模型的性能,并将模型应用于基于数据驱动的决策中去. 机器学习的三种不同的方法: …

sklearn模型中预测值的R2_score为负数
目录 正文评论区参考链接 正文
Sklearn.metrics下面的r2_score函数用于计算R(确定系数:coefficient of determination)。它用来度量未来的样本是否可能通过模型被很好地预测。
分值为 1 表示最好,但我们在使用过程中,…
承认自己的无知乃是开启智慧的大门
原文链接:https://xw.qq.com/amphtml/20200910A05NK300
苏格拉底申辩篇
文章内容
雅典的同胞,当我听到控诉我的人陈述以后,不知你们作何感想!不过他们强有力的说辞,使得我连自己是谁、都不知道了,这也达…
聚类sklearn实践
k均值聚类 K-Means
非常大的 n_samples, 中等的 n_clusters,将样本分成 n 组等方差的样本来聚类数据
metric:点之间的距离
步骤: 随机选K个聚集点 每个数据被赋值最近聚集点类别 使用每个聚集中心点更新 重复直到聚点移动小于阈值 返回K个…
sklearn常用函数整理
乱序
from sklearn.model_selection import ShuffleSplitK折交叉验证
from sklearn.model_selection import cross_val_score
cross_val cross_val_score(KNN, iris.data, iris.target, cv4,scoringneg_mean_squared_error)拆分数据集
from sklearn.model_selection import…
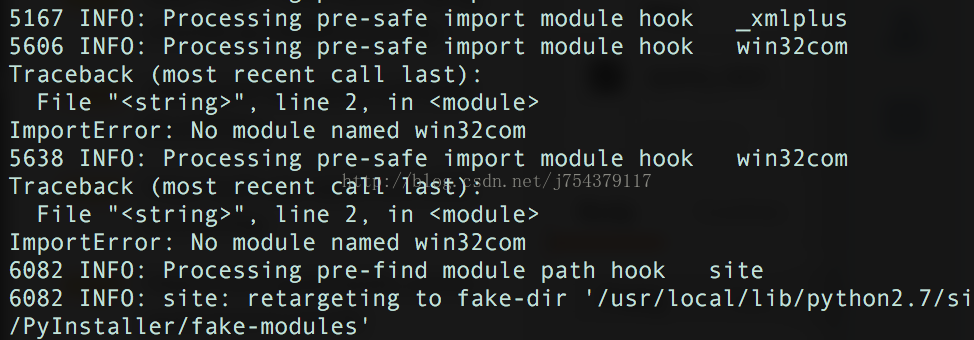
使用pyInstaller打包python下的sklearn工程
pyInstaller是一款python打包工具,它可以方便将python的所有依赖打包成一个可执行文件,所以它打包的文件只能在相同系统下运行。 本地使用的是Mac系统,python版本是2.7.12,代码是使用sklearn开发的机器学习相关的内容。在打包的时…
sklearn中的交叉验证与参数选择
大家可能看到交叉验证想到最多的就是sklearn里面数据集的划分方法train_test_split,实际上这只是数据交叉验证的数据方法,对模型的进行评分。这里我们将对仔细讲解sklearn中交叉验证如何判断模型是否过拟合,并进行参数选择。主要涉及一下方法…
模型选择与调优(交叉验证网格搜索)
交叉验证:
拿到训练数据,分为训练集和验证集。
将数据分成5分,其中一份作为验证集,经过5次测试,每次更换不同的验证集,得到5组模型的结果,最终取平均值,又称5折交叉验证。
交叉验…

机器学习文本特征提取
1.特征工程直接影响模型预测结果。python用sklearn库做特征工程
两种文本特征抽取方法(Count, tf-idf) (1)特征抽取API(统计单词次数)
sklearn.feature_extraction
python调用sklearn.feature_extracti…

多类别分类器(Machine Learning研习十八)
多类别分类器
二元分类器可以区分两个类别,而多类别分类器(也称为多叉分类器)可以区分两个以上的类别。
一些 Scikit-Learn 分类器(如 LogisticRegression、RandomForestClassifier 和 GaussianNB)能够原生处理多个类…
机器学习(十八):Bagging和随机森林
全文共10000余字,预计阅读时间约30~40分钟 | 满满干货(附数据及代码),建议收藏!
本文目标:理解什么是集成学习,明确Bagging算法的过程,熟悉随机森林算法的原理及其在Sklearn中的各参数定义和使用方法 代码…
机器学习基础17-基于波士顿房价(Boston House Price)数据集训练模型的整个过程讲解
机器学习是一项经验技能,实践是掌握机器学习、提高利用机器学习 解决问题的能力的有效方法之一。那么如何通过机器学习来解决问题呢? 本节将通过一个实例来一步一步地介绍一个回归问题。 本章主要介绍以下内容:
如何端到端地完成一个回归问题…

使用sklearn进行机器学习案例(1)
文章目录 案例一. 加州房价预测案例二. MNIST手写数字识别案例三. 波士顿房价预测 案例一. 加州房价预测
线性回归通过对训练集进行训练,拟合出一个线性方程,使得预测值与实际值之间的平均误差最小化。这个过程可以使用梯度下降法等优化算法来实现。即通…
sklearn保存和加载模型
刚接触sklearn, 后期再更新
References
[1] 【sklearn机器学习】模型的保存和恢复pickle python一对一视频讲解 经典实战 朝天吼数据_哔哩哔哩_bilibili

sklearn中的数据集使用
导库
from sklearn.datasets import load_iris
实现
# 加载数据集
iris load_iris()
print(f查看数据集:{iris})
print(f查看数据集的特征:{iris.feature_names})
print(f查看数据集的标签:{iris.target_names})
print(f查看数据集的描述…
机器学习——朴素贝叶斯(手动代码实现)
朴素的我,决定朴素地徒手实现贝叶斯算法! 摒弃sklearn 这个体贴善解人意把一切都打包封装好的妈妈 再见了sklearn 妈妈 我要自己手动实现 哪怕前方困难重重 哪怕我此刻还在发牢骚 但我还是要说,撒哟娜拉sklearn妈 看了知乎阿婆主的分析&#…

sklearn预测评估指标计算详解:准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1score
目录
前言
一、准确率 二、精确率
三、召回率
四、F1-score
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢 前言
很多时候需要对自己模型进行性能评估,对于一些理论上面的知识我想基本不用说明太多࿰…
机器学习框架sklearn之特征预处理:无量钢化
特征预处理
通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程。
包含内容: 数字型数据的无量钢化: ①归一化 ②标准化 为什么要进行归一化/标准化? 特征的单位或者大小相差较大,或者某特征的方差相比其他特…
PLS-DA分类的实现(基于sklearn)
目录
简单介绍
代码实现
数据集划分
选择因子个数
模型训练并分类
调用函数 简单介绍
(此处取自各处资料) PLS-DA既可以用来分类,也可以用来降维,与PCA不同的是,PCA是无监督的,PLS-DA是有监督的…

极简sklearn-使用决策树预测泰坦尼克号幸存者
泰坦尼克号幸存者数据集是kaggle竞赛中入门级的数据集,今天我们就来用决策树来预测下哪些人会成为幸存者。
数据集下载地址: https://download.csdn.net/download/ting4937/87630361 数据集中包含两个csv文件,data为训练用数据,test为测试集。
探索数据…
《精通特征工程》学习笔记(3):特征缩放的效果-从词袋到tf-idf
1.TF-IDF原理
tf-idf 是在词袋方法基础上的一种简单扩展,它表示词频 - 逆文档频率。tf-idf 计算的不是数据集中每个单词在每个文档中的原本计数,而是一个归一化的计数,其中每个单词的计数要除以这个单词出现在其中的文档数量。
词袋bow(w, …
sklearn——机器学习库相关数据集的使用,以及机器学习的相关算法介绍
系列文章专栏
机器学习以及matlab和数据分析
机器学习聚类——DBSCAN(Density-based spatial clustering of applications with noise,基于密度的聚类算法)
文章目录
系列文章专栏
sklearn前言介绍
一、sklearn数据集种类
二、Sklearn…
Sklearn数据预处理
sklearn.preprocessing 包提供了几个常见的实用功能和变换器类型,用来将原始特征向量更改为更适合机器学习模型的形式。
一般来说,机器学习算法受益于数据集的标准化。如果数据集中存在一些离群值,那么稳定的缩放或转换更合适。不同缩放、转…

OpenCV书签 #互信息的原理与相似图片搜索实验
1. 介绍
互信息(Mutual Information) 是信息论中的一个概念,用于衡量两个随机变量之间的关联程度。在图像处理和计算机视觉中,互信息常被用来度量两幅图像之间的相似性。
互信息可以看成是一个随机变量中包含的关于另一个随机变…
sklearn 计算 tfidf 得到每个词分数
from sklearn.feature_extraction.text import TfidfVectorizer# 语料库 可以换为其它同样形式的单词
corpus [list(range(-5, 5)),list(range(-6,4)),list(range(12)),list(range(13))]# corpus [
# [Two, wrongs, don\t, make, a, right, .],
# [The, pen, is, might…

sklearn.preprocessing.RobustScaler(解释和原理,分位数,四分位差)
提示:sklearn.preprocessing.RobustScaler(解释和原理,分位数,四分位差) 文章目录 [TOC](文章目录) 一、RobustScaler 是什么?二、代码1.代码2.输出结果 总结 提示:以下是本篇文章正文内容&…

Pytorch 深度学习笔记
Pytorch 深度学习笔记1. 环境及相关依赖2. 前导3. 部分概念3.1 深度学习3.2 tensor3.3 SVM3.4 超参数3.5 迁移学习4. 基于迁移学习的实现4.1 多分类4.1.1 加载数据4.1.2 训练4.1.3 保存和加载模型4.1.4 预测4.2 多标签4.2.1 加载数据集4.2.2 训练4.2.3 保存加载模型4.2.4 预测5…

机器学习SVC分类预测三个月后的股价
思路:通过学习近两年的每个季度报的基本面财务数据,建立模型,买入并持有预测三个月后会涨5%以上的股票,直到下一批季度报
数据采集:用到了大约10018行数据(已去除缺失值,不采用填充)…
sklearn加载外部数据集
1.使用numpy.loadtxt
2.解决Arff格式的方案
参考.arff files with scikit-learn? & LIAC-ARFF v2.1使用scipy.io.arff.loadarff
from scipy.io import arffdatasetarff.loadarff("D:/res/weather.nominal.arff")
print(dataset)
In [24]: type(dataset)
Out…

Python的库sklearn安装 bazel安装 cmake
Python的库sklearn安装
也可以用pip安装(如:pip installscikit-learn),但安装的位置不同,安装是包名不同(apt-get安装的python包一般前缀是python),python用的时候优先选择apt-get安…
多分类使用sklearn计算y_pred和y_prob
1.在开始计算时,给定类别为3类使用以下代码进行计算 y_pred classifier.predict(X_test)y_pred_prob classifier.predict_proba(X_test)发现发现输出的y_pred标签没有对应于y_pred_prob中每一个最大值对应位置的标签,找不到存在的问题。 print(y_test…
sklearn随机森林实现(备忘版)
scikit-learn是广泛使用的机器学习python库. sklearn已经实现了决策树及集成模型, 下面是随机森林分类算法实现的示例代码.
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
datasetpd.read_table(/path/to/DataSet/Classificat…

【机器学习】进阶学习:详细解析Sklearn中的MinMaxScaler---原理、应用、源码与注意事项
【机器学习】进阶学习:详细解析Sklearn中的MinMaxScaler—原理、应用、源码与注意事项 这篇文章的质量分达到了97分,虽然满分是100分,但已经相当接近完美了。请您耐心阅读,我相信您一定能从中获得不少宝贵的收获和启发~ …
sklearn库--ML算法全部代码整理
此代码包括了机器学习所有基本算法,非常适合初学者,如果有任何问题,欢迎提问,此代码会不断更新…
# 加载包
import numpy as np
import pandas as pd
import osfrom sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from skl…
sklearn.model_selection.learning_curve的详细介绍(包含ShuffleSplit()介绍)
提示:sklearn.model_selection.learning_curve的详细介绍 文章目录 1、需求分析2、learning_curve主要输出参数3、learning_curve主要参数4、learning_curve作用5、learning_curve代码6、ShuffleSplit() 1、需求分析
通过参数train_size选取…
ModuleNotFoundError: No module named ‘sklearn.cross_validation
当运行机器学习sklearn库中的
from sklearn.cross_validation import train_test_split出现:**ModuleNotFoundError: No module named ‘sklearn.cross_validation’**的错误;
一、解决办法:
将上面报错的语句改为下方的代码即可ÿ…
涛哥聊Python | auto-sklearn,一个非常好用的 Python 库!
本文来源公众号“涛哥聊Python”,仅用于学术分享,侵权删,干货满满。
原文链接:auto-sklearn,一个非常好用的 Python 库!
大家好,今天为大家分享一个非常好用的 Python 库 - auto-sklearn。
G…
LogisticRegression 与 LogisticRegressionCV 的区别
LogisticRegression 和 LogisticRegressionCV 是 scikit-learn 库中用于逻辑回归的两个类,它们之间的区别如下。
1、LogisticRegression
LogisticRegression 是用于二分类或多分类问题的逻辑回归模型。可以使用不同的优化算法(如拟牛顿法、坐标下降法&…
安装sklearn包错误解决以及 scikit-learn简介
安装sklearn包错误解决以及 scikit-learn简介
利用
pip install sklearn时出现错误
pip install sklearn
Looking in indexes: https://mirrors.aliyun.com/pypi/simple/
Collecting sklearnUsing cached https://mirrors.aliyun.com/pypi/packages/b9/0e/b2a4cfaa9e12b9ca4…
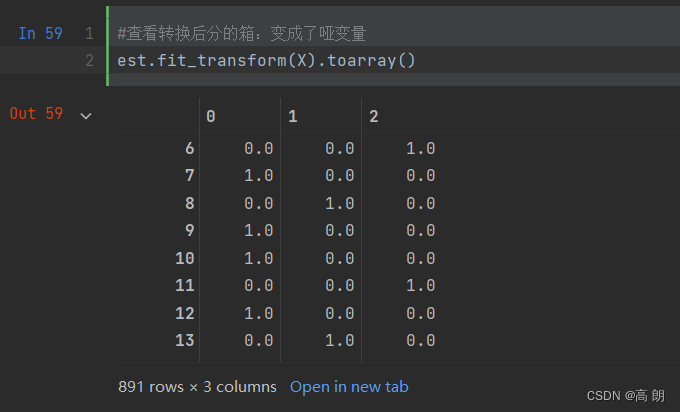
【机器学习】sklearn对数据预处理
文章目录 数据处理步骤观察数据数据无量纲化缺失值处理处理分类型特征处理连续型特征 数据处理步骤
数据无量纲化缺失值处理处理分类型特征:编码与哑变量处理连续型特征:二值化与分段 观察数据
通过pandas读取数据,通过head和info方法大致查…
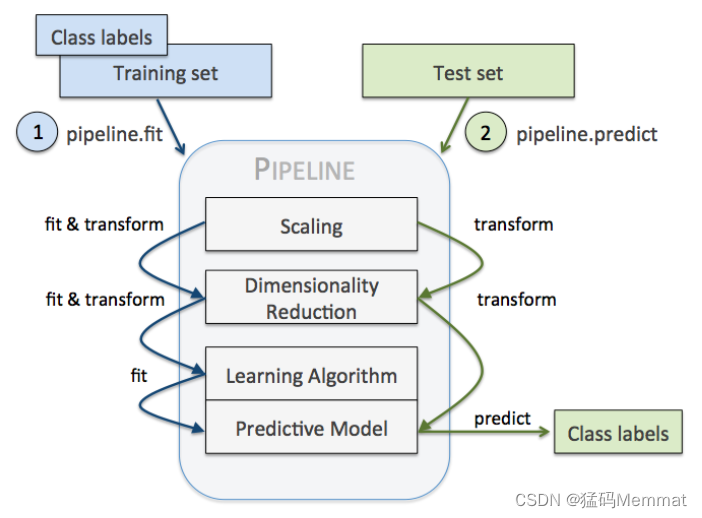
机器学习tip:sklearn中的pipeline
文章目录 1 加载数据集2 构思算法的流程3 Pipeline执行流程的分析ReferenceStatement 一个典型的机器学习构建包含若干个过程
源数据ETL数据预处理特征选取模型训练与验证
一个典型的机器学习构建包含若干个过程
以上四个步骤可以抽象为一个包括多个步骤的流水线式工作&…
【Python机器学习】sklearn.datasets分类任务数据集
如何选择合适的数据集进行机器学习的分类任务?
选择合适的数据集是进行任何机器学习项目的第一步,特别是分类任务。数据集是机器学习任务成功的基础。没有数据,最先进的算法也无从谈起。
本文将专注于sklearn.datasets模块中用于分类任务的数据集。这些数据集覆盖了各种场…
(完全解决)如何输入一个图的权重,然后使用sklearn进行谱聚类
文章目录 背景输入点直接输入邻接矩阵 背景
网上倒是有一些关于使用sklearn进行谱聚类的教程,但是这些教程的输入都是一些点的集合,然后根据谱聚类的原理,其会每两个点计算一次亲密度(可以认为两个点距离越大,亲密度越…

如何用sklearn对随机森林调参
文章目录 一、概述二、实操1、导入相关包2、导入乳腺癌数据集,建立模型3、调参 三、总结 Link:https://zhuanlan.zhihu.com/p/126288078 Author:陈罐头 一、概述
sklearn是目前python中十分流行的用来实现机器学习的第三方包,其中…

【教学类-17-03】20231105《世界杯随机参考图七巧板 3份一页》(大班)
效果展示:
单页效果 多页效果 预设样式: 背景需求:
2022年11月24日,大1班随机抽取的9位幼儿制作了9张拼图,发现以下三个问题:
1、粉红色辅助纸选择量多——9份作业有4位幼儿的七巧板人物是粉红色的
2、…
机器学习/sklearn 笔记:K-means,kmeans++
1 K-means介绍
1.0 方法介绍
KMeans算法通过尝试将样本分成n个方差相等的组来聚类,该算法要求指定群集的数量。它适用于大量样本,并已在许多不同领域的广泛应用领域中使用。KMeans算法将一组样本分成不相交的簇,每个簇由簇中样本的平均值描…
sklearn教程:iris鸢尾花数据集数据分析
文章目录 数据集介绍导入数据集查看数据标签、属性和介绍查看数据整理为dataframe数据indo()查看数据类型和是否缺失describe() 提供数值型变量的描述性统计变量赋值标签编码分割训练集测试集查看X y 维度可视化分析箱线图查看数据分布和异常值直方图查看数值型数据分布密度图查…
sklearn教程:titanic泰坦尼克号数据集
文章目录 数据集介绍导入数据集info()显示数据类型和是否缺失describe()数据描述性统计数据可视化-探索性分析EDA填充缺失值之后的可视化类别变量的相关关系数据集介绍
这个数据集是基于泰坦尼克号中乘客逃生的,泰坦尼克号出事故,船上的乘客的一些信息被记录在这张表中。现在…
【机器学习技巧】机器学习模型的两种存储方式:pickle与joblib模块
目录1. 构建待存储的示例模型--鸢尾花数据集2. 模型存储2.1 使用sklearn中的joblib存储2.2 使用python自带的pickle模块存储模型本文主要介绍了两种机器学习模型的存储与读取方式,方便我们将训练好的模型直接存储起来,方便下次直接使用该模型进行预测。1…

机器学习 sklearn 中的超参数搜索方法
✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。 🍎个人主页:小嗷犬的个人主页 🍊个人网站:小嗷犬的技术小站 🥭个人信条:为天地立心&…
ML@sklearn@ML流程@part1
文章目录MLsklearnML流程part1refdocumentsapi术语参考glossary of common Terms and api elementsgetting startedFitting and predicting: estimator basicsTransformers and pre-processors数据的转换和预处理StandardScaler中心化和缩放Centering and scaling标准化相关理论…
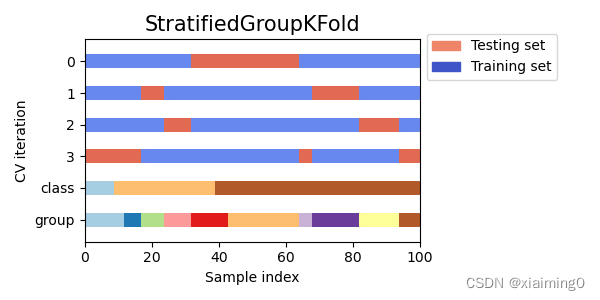
StratifiedGroupKFold解释和代码实现
StratifiedGroupKFold解释和代码实现 文章目录 一、StratifiedGroupKFold解释和代码实现是什么?二、 实验数据设置2.1 实验数据生成代码2.2 代码结果 三、实验代码3.1 实验代码3.2 实验结果3.3 结果解释 四、样本类别类别不平衡 一、StratifiedGroupKFold解释和代码…
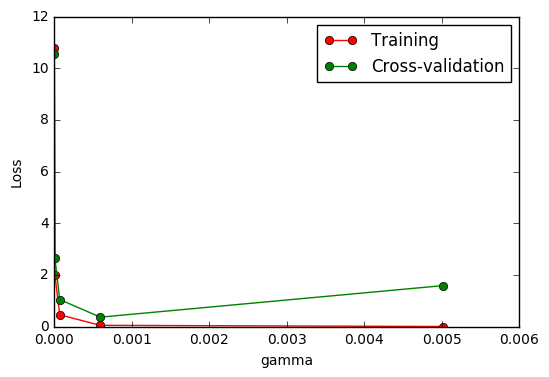
Scikit-learn (sklearn)速通 -【莫凡Python学习笔记】
视频教程链接:【莫烦Python】Scikit-learn (sklearn) 优雅地学会机器学习
视频教程代码
scikit-learn官网
莫烦官网学习链接
本人matplotlib、numpy、pandas笔记
1 为什么学习
Scikit learn 也简称 sklearn, 是机器学习领域当中最知名的 python 模块之一.
Sk…
Sklearn 聚类算法的性能评估
聚类算法的性能评估是什么?
聚类是无监督学习的一种常用技术,用于将相似的数据点分组在一起。然而在实施聚类算法后,一个关键的问题便是如何评估其性能或质量。由于聚类是无监督的,因此评估其性能相对更为复杂。本文将探讨多种用于评估聚类性能的指标,包括肘部法则、轮廓…

快速入门python机器学习
文章目录 机器学习概述1.1 人工智能概述机器学习与人工智能、深度学习1.1.2 机器学习、深度学习能做些什么 1.2 什么是机器学习1.2.1 定义1.2.2 解释1.2.3 数据集构成 1.3 机器学习算法分类1.3.1 总结1.3.2 练习1.3.3 机器学习算法分类 1.4 机器学习开发流程(了解&a…
sklearn 笔记:neighbors.NearestNeighbors 自定义metric
1 数据
假设我们有这样的一个数据tst_lst,表示的是5条轨迹的墨卡托坐标,我们希望算出逐点的曼哈顿距离之和,作为两条轨迹的距离
[array([[11549759.51313693, 148744.89246911],[11549751.49813359, 148732.97804463],[11549757.620705…

机器学习算法---分类
当然,让我为您提供更详细的机器学习算法介绍,重点在于每种算法的原理、优缺点,并在注意事项中特别提到它们对非平衡数据和高维稀疏数据的适应性。
1. 决策树(Decision Trees)
原理: 决策树通过学习简单的…

【DWJ_1703225514】基于Sklearn航空公司服务质量分析
【Talk is cheap】
# 导入库
import warnings
warnings.filterwarnings(ignore)import pandas as pd import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams[font.sans-serif] [SimHei]
plt.rcParams[axes.unicode_minus] False
%matplotlib inlinefrom skl…
![解决Error in rawToChar(block[seq_len(ns)]) :](https://img-blog.csdnimg.cn/e3d61a20f58b4f07990207af4f6b683a.png)
解决Error in rawToChar(block[seq_len(ns)]) :
今天运行harmony的tutorial时,发现有一个错误,就是
singlecellmethods包需要安装,该包的网址在于 https://github.com/immunogenomics/singlecellmethods
但是我使用 install.packages("/Volumes/Elements SE/单细胞数据集/harmony201…
Sklearn、TensorFlow 与 Keras 机器学习实用指南第三版(九)
原文:Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow 译者:飞龙 协议:CC BY-NC-SA 4.0 附录 A:机器学习项目清单
此清单可以指导您完成机器学习项目。有八个主要步骤: 构建问题并全局看问题。 …
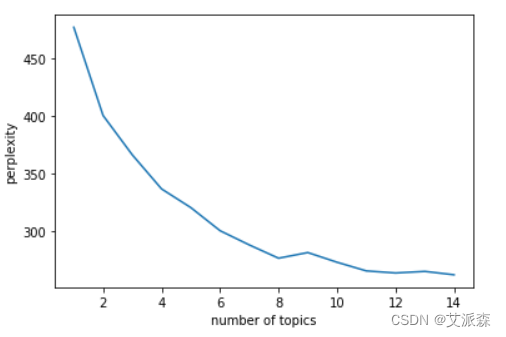
基于sklearn实现LDA主题模型(附实战案例)
目录 LDA主题模型
1.LDA主题模型原理
2.LDA主题模型推演过程
3.sklearn实现LDA主题模型(实战)
3.1数据集介绍
3.2导入数据
3.3分词处理 3.4文本向量化
3.5构建LDA模型
3.6LDA模型可视化
3.7困惑度 LDA主题模型 1.LDA主题模型原理 其实说到LDA…

使用sklearn,报错Library not loaded: @rpath/libgfortran.3.dylib
因为需要使用sklearn,去做一些数据分析,所以使用conda命令进行安装 conda install scikit-learn 在安装完成之后,导入,并使用拟合优度R2函数评估,发生如下报错; import sklearn as sk r2 sk.metrics.r2_sc…
sklearn多项式回归和线性回归
什么是线性回归? 回归分析是一种统计学方法,用于研究自变量和因变量之间的关系。它是一种建立关系模型的方法,可以帮助我们预测和解释变量之间的相互作用。
回归分析通常用于预测一个或多个因变量的值,这些因变量的值是由一个或多…
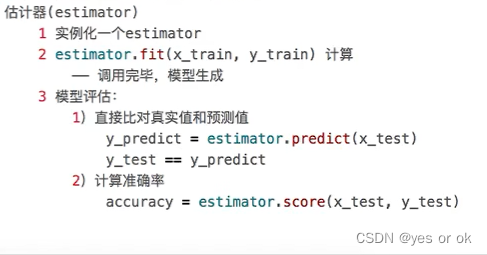
四、分类算法 - sklearn转换器和估算器
目录
1、sklearn转换器和估算器
1.1 转换器 - 特征工程的父类
1.2 估计器 - sklearn机器学习算法的实现 目标值:分类
sklearn转换器和估算器KNN算法模型选择和调优朴素贝叶斯算法决策树随机森林
1、sklearn转换器和估算器
1.1 转换器 - 特征工程的父类 1.2 估…

【4 - 降维算法PCA和SVD - 原理部分】菜菜sklearn机器学习
课程地址:《菜菜的机器学习sklearn课堂》_哔哩哔哩_bilibili
第一期:sklearn入门 & 决策树在sklearn中的实现第二期:随机森林在sklearn中的实现第三期:sklearn中的数据预处理和特征工程第四期:sklearn中的降维算法…

ModaHub魔搭社区:自动化机器学习Auto-Sklearn全面详细教程
Auto-Sklearn的简介
Auto-Sklearn(基于scikit-learn库的自动化的机器学习工具)的概述
简介
Auto-Sklearn,在2015年由德国图宾根大学的研究人员提出的,最初的版本于2016年发布。auto-sklearn基于scikit-learn库进行开发,支持多种机器学习任务,包括分类、回归、时间序列…

Scikit-LLM:将大语言模型整合进Sklearn的工作流
我们以前介绍过Pandas和ChaGPT整合,这样可以不了解Pandas的情况下对DataFrame进行操作。现在又有人开源了Scikit-LLM,它结合了强大的语言模型,如ChatGPT和scikit-learn。但这个并不是让我们自动化scikit-learn,而是将scikit-learn…
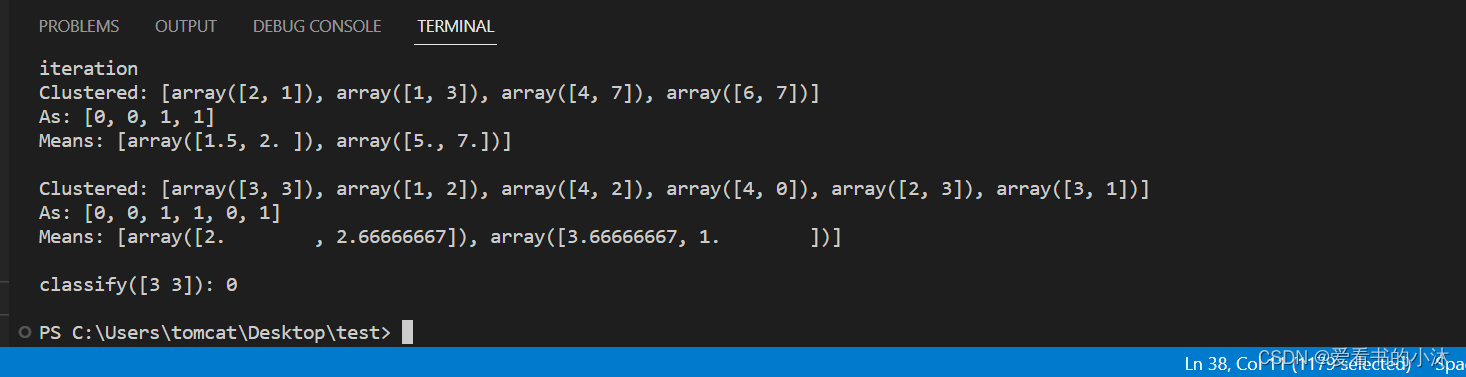
【小沐学NLP】Python实现K-Means聚类算法(nltk、sklearn)
文章目录 1、简介1.1 机器学习1.2 K 均值聚类1.2.1 聚类定义1.2.2 K-Means定义1.2.3 K-Means优缺点1.2.4 K-Means算法步骤 2、测试2.1 K-Means(Python)2.2 K-Means(Sklearn)2.2.1 例子1:数组分类2.2.2 例子2࿱…
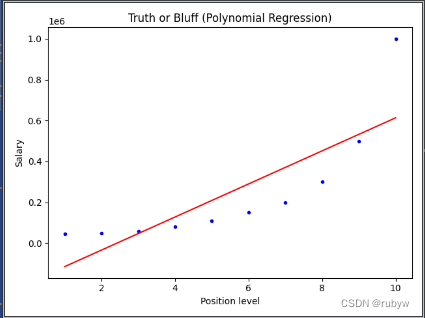
Python多项式回归sklearn
一、理论介绍
多项式回归是一种回归分析的方法,它通过使用多项式函数来拟合数据。与简单线性回归不同,多项式回归可以更灵活地适应数据的曲线特征,因为它可以包含多个特征的高次项。
多项式回归的一般形式为:
在实际应用中&am…
Python包sklearn画ROC曲线和PR曲线
前言
关于ROC和PR曲线的介绍请参考: 机器学习:准确率(Precision)、召回率(Recall)、F值(F-Measure)、ROC曲线、PR曲线
参考: Python下使用sklearn绘制ROC曲线(超详细) Python绘图|Python绘制ROC曲线和PR曲线
源码
…
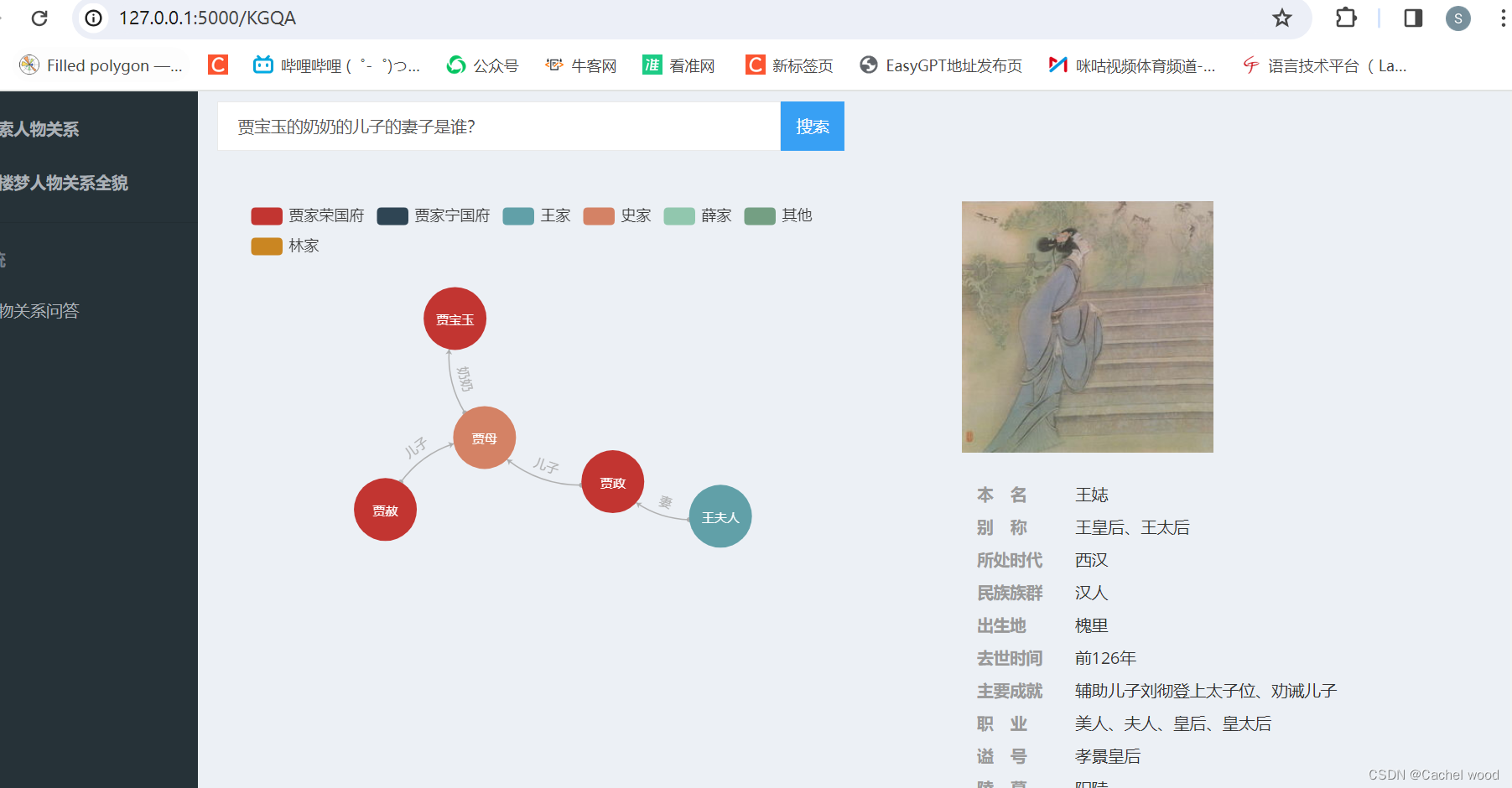
毕业设计:基于知识图谱的《红楼梦》人物关系可视化
文章目录 项目介绍部署步骤项目运行 项目介绍
github地址:https://github.com/chizhu/KGQA_HLM?tabreadme-ov-file
基于知识图谱的《红楼梦》人物关系可视化:应该是重庆邮电大学林智敏同学的毕业设计,在学习知识图谱的过程中参考使用。
文…
sklearn教程:boston波士顿房价数据集
文章目录 数据集介绍导入库划分训练集测试集导入DataFrame创建学习模型 KNN Linear DecisionTree SVR训练模型预测数据绘图可视化数据标准化模型训练和预测数据集介绍
Boston数据集是一个经典的回归分析数据集,包含了美国波士顿地区的房价数据以及相关的属性信息。该数据集共…
KNN最近邻节点算法分类回归预测基础算法、优化方案及python代码实现
0.基本介绍:
K-NearestNeighbor,最近邻节点算法一种惰性学习算法,存储已有数据样本,推理新样本时计算与其距离最近的K个已有样本点,通过投票(分类)或者加权平均(回归)的…
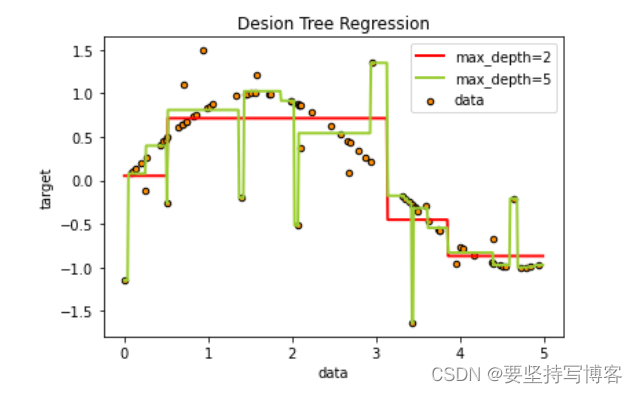
机器学习决策树、回归树 sklearn-day1
#文章很多内容来自菜菜老师的课件。仅做笔记一、决策树
1、模块 2、sklearn基本建模流程
#分类树对应的代码
from sklearn import tree #导入需要的模块
clf tree.DecisionTreeClassifier() #实例化
clf clf.fit(X_train,y_train) #用训练集数据训练模型
result clf…
【机器学习】skit-learn中LSI模型的实现
参考文献
[1]sklearn_api.lsimodel – Scikit learn wrapper for Latent Semantic Indexing [2]Python models.LsiModel方法代码示例
RandomForestClassifier 与 GradientBoostingClassifier 的区别
RandomForestClassifier(随机森林分类器)和GradientBoostingClassifier(梯度提升分类器)是两种常用的集成学习方法,它们之间的区别分以下几点。
1、基础算法
RandomForestClassifier:随机森林分类器是基于…
用sklearn实现线性回归和岭回归
此文为ai创作,今天写文章的时候发现创作助手限时免费,想测试一下,于是就有了这篇文章,看的出来,效果还可以,一行没改。
线性回归
在sklearn中,可以使用线性回归模型做多变量回归。下面是一个示…
已解决:stability_selection模块报错got an unexpected keyword argument ‘normalize‘等问题
1.stability_selection模块问题
(1) 多余参数
got an unexpected keyword argument ‘normalize‘
got an unexpected keyword argument ‘penalty’(2)导库问题
(3)函数不收敛/数据标准化问题
(4)项目自带的示例跑不通问题
2.stability_selection模块问题解决
【问…
数据分析:人工智能篇
文章目录 第三章 数据可视化库matplotlib3.1 matplotlib基本绘图操作3.2 plot的线条和颜色3.3 条形图分析3.4 箱型图分析3.5 直方图分析3.6 散点图分析3.7 图表的美化 第四章 数据预测库Sklearn4.1 sklearn预测未来4.2 回归数据的预测4.2.1 回归数据的切分4.2.2 线性回归数据模…

sklearn实现k-means算法
from sklearn.cluster import KMeans
import numpy as np
import matplotlib.pyplot as plt# 载入数据
data np.genfromtxt("kmeans.txt", delimiter" ")
# 设置k值
k 4 # 训练模型
model KMeans(n_clustersk)
model.fit(data)# 分类中心点坐标
center…
【解决】sklearn-LabelEncoder遇到没在编码规则里的新值
文章目录 一、问题描述二、解决方法Reference 一、问题描述
问题:sklearn-LabelEncoder 遇到没在编码规则里的新值
二、解决方法
方法一:直接保存old_data和encoder_data和之间的映射关系,字典或者下面的csv格式里都可以。
for col in be…
【机器学习】集成学习Boosting
文章目录 集成学习BoostingAdaBoost梯度提升树GBDTXGBoostxgboost库sklearn APIxgboost库xgboost应用 集成学习
集成学习(ensemble learning)的算法主要包括三大类:装袋法(Bagging),提升法(Boo…
sklearn 特征选择
select_Ksklearn.feature_selection.SelectKBest(mutual_info_classif,k10).fit(features_train,label)
机器学习之集成学习与sklearn使用
一、个体与集成
集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务,集成学习的一般结构:先产生一组“个体学习器”,再用某种策略将它们结合起来。 sklearn中文;sklearn英文. 目的:把多个…
ImportError: cannot import name ‘joblib‘ from ‘sklearn.externals‘
感谢阅读原因排查解决方法安装joblib导入方法更换原因排查
经查阅资料,版本0.22之后的 scikit_learn 中就除掉了 joblib 这个函数或包。需要直接下载安装 joblib 这个包
解决方法
安装joblib
运行
pip install joblib 或者 在编译器直接搜索库安装joblib
导入…
机器学习实战:基于sklearn的工业蒸汽量预测
文章目录 写在前面工业蒸汽量预测1.基础代码2.模型训练3.模型正则化4.模型交叉验证5.模型超参空间及调参6.学习曲线和验证曲线 写在后面 写在前面 本期内容:基于机器学习的工业蒸汽量预测 实验环境: anaconda python sklearn 注:本专栏内所有…

sklearn机器学习通用解决方案
从 START 开始,首先看数据的样本是否 >50,小于则需要收集更多的数据。
由图中,可以看到算法有四类,分类,回归,聚类,降维。
其中 分类和回归是监督式学习,即每个数据对应一个 la…
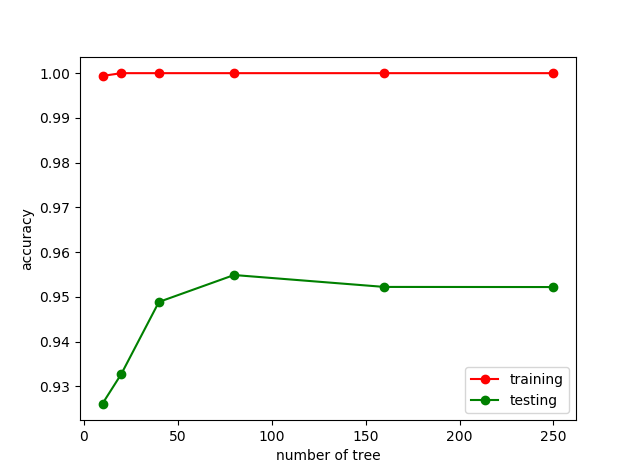
sklearn模型调优(判断是否过过拟合及选择参数)
sklearn模型调优(判断是否过过拟合及选择参数)这篇博客主要介绍两个方面的东西,其实就是两个函数:
1. learning_curve():这个函数主要是用来判断(可视化)模型是否过拟合的,关于过拟…
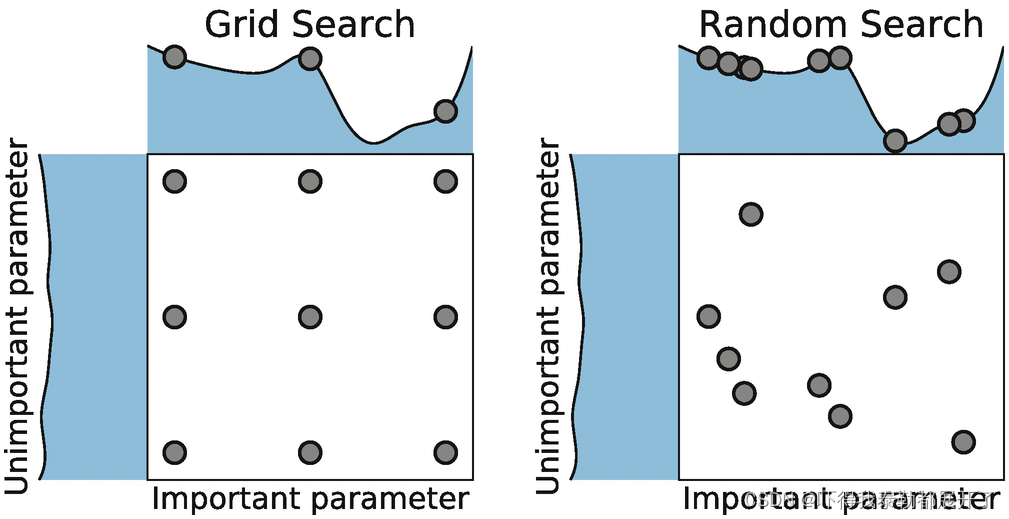
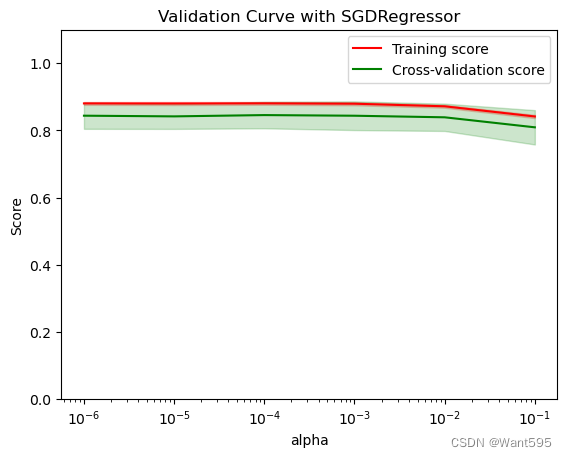
超参数优化--随机网格法
随机网格搜索RandomizedSearchCV 在网格搜索时我们提到,伴随着数据和模型的复杂度提升,网格搜索所需要的时间急剧增加。以随机森林算法为例,如果使用过万的数据,搜索时间则会立刻上升好几个小时。因此,我们急需寻找到一…

第2关:动手实现knn算法
任务描述 本关任务:使用python实现knn算法,并对手写数字进行识别。 相关知识 为了完成本关任务,你需要掌握:1.加权投票,2.knn算法流程。 数据集介绍 手写数字数据集一共有1797个样本,每个样本有64个特征。每…
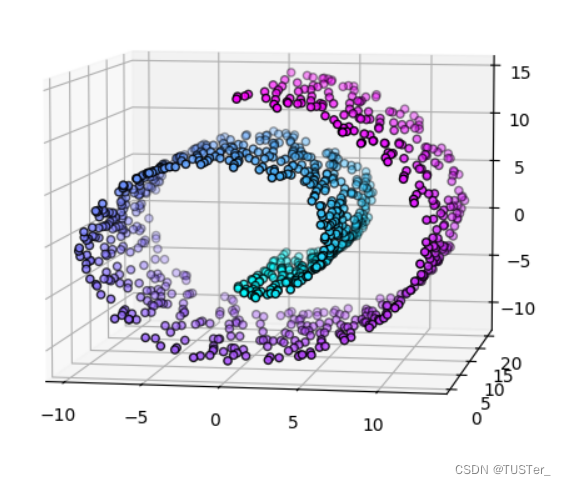
【自然语言处理】利用sklearn库函数绘制三维瑞士卷
一,原理介绍
sklearn.datasets.make_swiss_roll()函数提供了三维瑞士卷的数据集,我们可以利用他来生成瑞士卷,该函数的用法见sklearn官方文档:官网文档:sklearn.datasets.make_swiss_roll&…
scikit-learn 普通最小二乘法
scikit-learn 普通最小二乘法什么是普通最小二乘法?参考文献什么是普通最小二乘法?
线性回归模型的数学表达式如下: y^(w,x)w0w1x1…wpx1\hat{y}(w, x)w_{0}w_{1} x_{1}\ldotsw_{p} x_{1}y^(w,x)w0w1x1…wpx1
其中 w0,w1,...,w…

sklearn中的朴素贝叶斯
1 概述
1.1 真正的概率分类器
在许多分类算法应用中,特征和标签之间的关系并非是决定性的。如想预测一个人究竟是否能在泰坦尼克号海难中生存下来,可以建一棵决策树来学习训练集。在训练中,其中一个人的特征为30岁、男、普通舱,…
最小二乘法构建线性回归方程
文章目录一、线性回归的意义二、线性回归的使用1.在Excel中练习线性回归2.使用jupyter来做一元线性回归分析一、线性回归的意义
线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。在线…
多线程+PyQt5打包的EXE程序无响应 功能不执行 弹出很多相同窗口
问题背景描述:项目程序涉及到机器学习,需要实现机器学习模型的寻参和训练,封装到应用程序中,由于模型训练需要较多时间,所以会出现程序打包成exe之后,触发模型训练之后会出现程序“无响应”的卡死现象&…
sklearn.metrics.roc_auc_score(二分类/多分类/多标签)
数据格式 y_true: (n_samples,) or (n_samples, n_classes) y_score: (n_samples,) or (n_samples, n_classes)
样例
二分类
>>> from sklearn.datasets import load_breast_cancer
>>> from sklearn.linear_model import Logist…
机器学习——决策树与随机森林
机器学习——决策树与随机森林 文章目录 前言一、决策树1.1. 原理1.2. 代码实现1.3. 网格搜索1.4. 可视化决策树 二、随机森林算法2.1. 原理2.2. 代码实现 三、补充(过拟合与欠拟合)总结 前言
决策树和随机森林都是常见的机器学习算法,用于分…
使用sklearn函数对模型进行交叉验证
使用sklearn函数对模型进行交叉验证 交叉验证用来做什么sklearn 中的函数 交叉验证用来做什么
交叉验证(Cross-Validatio),是用于在驯良过程中对训练模型的性能和参数进行评估选择的技术。
它的意义在于能够充分利用优先的数据集࿰…

交叉验证的种类和原理(sklearn.model_selection import *)
交叉验证的种类和原理 所有的来自https://scikit-learn.org/stable/modules/cross_validation.html#cross-validation-iterators并掺杂了自己的理解。 文章目录 前言一、基础知识1.1 交叉验证图形表示1.2 交叉验证主要类别 二、部分交叉验证函数(每类一个࿰…
3、【正式建模】之数据划分、模型选择以及模型评估、调优
前情回顾之预处理from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import StandardScaler, Imputer
from sklearn.feature_selection import VarianceThreshold
from sklearn.decomposition import PCA自带数据集导入 load* 和 fetc…
机器学习之网格搜索技术,如何在Auto-sklearn中应用网格搜索技术
文章目录 一,机器学习中的网格搜索技术是怎么回事二,通俗解释三,在一般情况下使用网格搜索技术四,GridSearchCV网格搜索技术的原理五,如何在Auto-sklearn中使用网格搜索技术1. Auto-sklearn实际用应用中一般不会使用网…
sklearn.preprocessing模块介绍
数据预处理
Binarizer: 二值化
用于将数值特征二值化。它将特征值与给定的阈值进行比较,并将特征值转换为布尔值(0 或 1),取决于特征值是否超过阈值
Binarizer(*, threshold0.0, copyTrue)参数:
threshold…

特征工程---特征预处理
1. 什么是特征预处理
1.1 特征预处理定义
通过⼀些转换函数将特征数据转换成更加适合算法模型的特征数据过程
为什么我们要进⾏归⼀化/标准化? 特征的单位或者⼤⼩相差较⼤,或者某特征的⽅差相⽐其他的特征要⼤出⼏个数量级,容易影响&…

sklearn机器学习库(一)sklearn中的决策树
sklearn机器学习库(一)sklearn中的决策树
sklearn中决策树的类都在”tree“这个模块之下。
tree.DecisionTreeClassifier分类树tree.DecisionTreeRegressor回归树tree.export_graphviz将生成的决策树导出为DOT格式,画图专用tree.export_text以文字形式输出树tree.…

【Sklearn】基于最中心分类器算法的数据分类预测(Excel可直接替换数据)
【Sklearn】基于最中心分类器算法的数据分类预测(Excel可直接替换数据) 1.模型原理2.模型参数3.文件结构4.Excel数据5.下载地址6.完整代码7.运行结果 1.模型原理
最近中心分类器(Nearest Centroid Classifier)也被称为近似最近邻…

【Sklearn】基于K邻近算法的数据分类预测(Excel可直接替换数据)
【Sklearn】基于K邻近算法的数据分类预测(Excel可直接替换数据) 1.模型原理模型原理:数学模型: 2.模型参数3.文件结构4.Excel数据5.下载地址6.完整代码7.运行结果 1.模型原理
K最近邻(K-Nearest Neighbors,…
【Sklearn】基于朴素贝叶斯算法的数据分类预测(Excel可直接替换数据)
【Sklearn】基于朴素贝叶斯算法的数据分类预测(Excel可直接替换数据) 1.模型原理2.模型参数3.文件结构4.Excel数据5.下载地址6.完整代码7.运行结果 1.模型原理
模型原理:
朴素贝叶斯分类是基于贝叶斯定理的一种分类方法。它假设特征之间相互…

【Sklearn】基于决策树算法的数据分类预测(Excel可直接替换数据)
【Sklearn】基于决策树算法的数据分类预测(Excel可直接替换数据) 1.模型原理1.1 模型原理1.2 数学模型 2.模型参数3.文件结构4.Excel数据5.下载地址6.完整代码7.运行结果 1.模型原理
决策树是一种基于树状结构的分类和回归模型,它通过一系列…

【字典学习+稀疏编码Sparse Encoding】简单介绍与sklearn的实现方式
文章目录 1、字典学习与稀疏编码2、sklearn的实现3、示例 1、字典学习与稀疏编码
简单来说,稀疏编码就是把输入向量(信号)/ 矩阵(图像)表示为稀疏的系数向量和一组超完备基向量(字典)的线性组合…

【Sklearn】基于随机森林算法的数据分类预测(Excel可直接替换数据)
【Sklearn】基于随机森林算法的数据分类预测(Excel可直接替换数据) 1.模型原理1.1 模型原理1.2 数学模型 2.模型参数3.文件结构4.Excel数据5.下载地址6.完整代码7.运行结果 1.模型原理
随机森林(Random Forest)是一种集成学习方法…
sklearn打乱数据顺序
import sklearn
import numpy as np
X np.array([[1, 2], [3, 4], [5, 6]])
Y np.array([[1], [2], [3]])
print(X)
print(Y)
[[1 2][3 4][5 6]]
[[1][2][3]]
X, Y sklearn.utils.shuffle(X, Y)
print(X)
print(Y)
[[3 4][5 6][1 2]]
[[2][3][1]]
【NGBoost实战】
NGBoost实战 一级目录二级目录三级目录 ngboost分类实战常用参数介绍基学习器定义定义训练函数 一级目录
二级目录
三级目录
ngboost分类实战
常用参数介绍
n_estimators: 学习器数量learning_rate: 学习率minibatch_frac: 每次迭代的样本比例col_sample: 每次迭代的特征比…
sklearn - 决策树和随机森林
文章目录决策树回归模型决策树分类器可视化随机森林分类器特征重要性选择随机森林中的重要特征处理不均衡的分类控制决策树的规模通过 boosting 提高性能使用袋外误差(Out-of-bag Error)评估随机森林模型决策树回归模型 from sklearn import datasets
f…
机器学习实战-系列教程2:线性回归1(项目实战、原理解读、源码解读)
🌈🌈🌈机器学习 实战系列 总目录 本篇文章的代码运行界面均在Pycharm中进行 本篇文章配套的代码资源已经上传 机器学习实战-系列教程1:线性回归入门教程 机器学习实战-系列教程2:线性回归1 机器学习实战-系列教程3&am…
机器学习中软投票和硬投票的不同含义和理解
分类问题:目标值是离散型的,比如男女,大小等 回归问题:目标值是连续的,在某一区间内任意取值,比如房价等 设置一个场景,比如对于今天音乐会韩红会出现的概率三个人三个观点 A:韩红出…
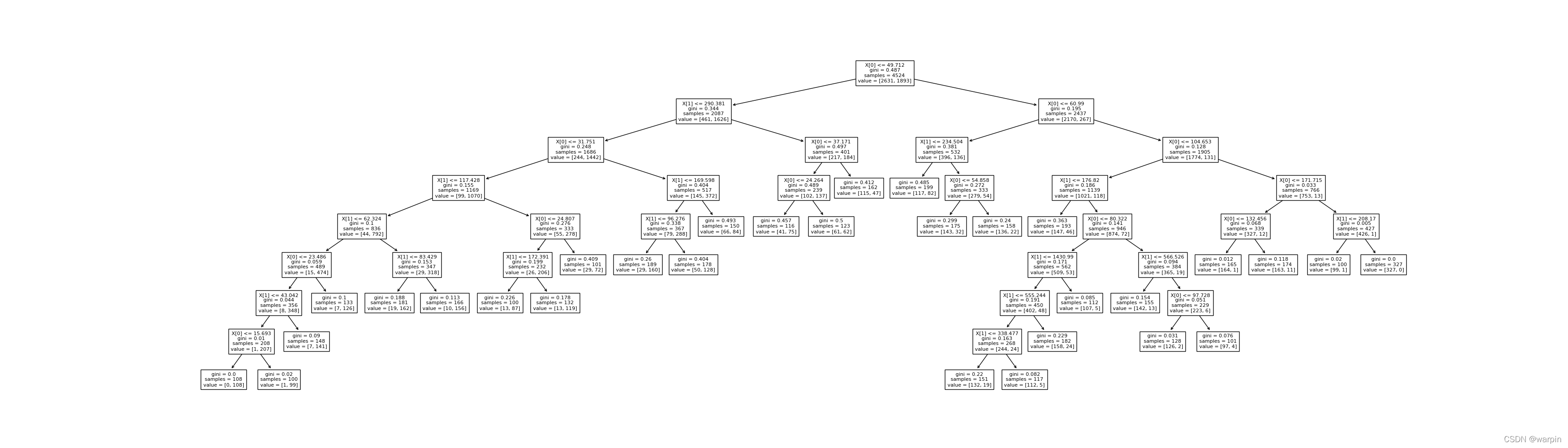
sklearn决策树可视化
过去,关于sklearn决策树可视化的教程大部分都是基于Graphviz(一个图形可视化软件)的。
Graphviz的安装比较麻烦,并不是通过pip install就能搞定的,因为要安装底层的依赖库。
现在,自版本0.21以后…
线性回归-scikit-learn
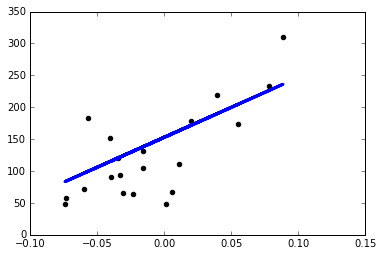
线性回归即是我们希望能通过学习来得到一个各属性线性组合的函数,函数的各项系数表明了该属性对于最后结果的重要性,可以用以下公式表达:yˆ(ω,x)ω1x1ω2x2...ωpxpb普通最小二乘法
线性回归试图让各个点到回归直线上的距离和最小…
导入sklearn报错:No module named ‘threadpoolctl‘
前言
sklearn的安装
注意sklearn安装不是pip install sklearn,而是pip install scikit-learn; 使用清华源安装sklearn,windows中使用自己的python环境,在命令行输入如下:
pip install scikit-learn -i https://pypi.tuna.tsing…

【机器学习与遥感】sklearn与rasterio实现遥感影像监督分类
在学习遥感的过程中,我们都了解到了监督分类与非监督分类,二者是遥感解译的基础。之前更多的是使用Erdas与ENVI来进行这两种分类。这里使用python语言,基于机器学习库sklearn与遥感影像处理库rasterio,使用kmeans动态聚类方法实现…
Centos7 安装sklearn gcc: error: ‘-Qunused-arguments’
1. 在centos7上安装sklearn各种报错
gcc: error: unrecognized command line option ‘-Qunused-arguments’
gcc: error: unrecognized command line option ‘-Qunused-arguments’
gcc: error: unrecognized command line option ‘-Qunused-arguments’
google下应该是pi…
基于逻辑回归的入侵检测
1、简介
基于KDDCUP99数据集,利用逻辑回归方法进行入侵检测学习。
2、主要步骤
第一步,数据预处理:对KDDCUP99原始数据集进行处理,使其成为适合进行学习的形式。进行特征选择,降低维度。 第二步,调参&am…

SVM支持向量机与sklearn支持向量机分类
一、SVM的基本概念
1、总览: 在之前的机器学习基本知识中,总结了支持向量机的相关基础概念。 支持向量机(Support Vector Machine, SVM)是定义在特征空间上间隔最大的线性分类器。它是一种二分类模型,当采用核技巧之后&…
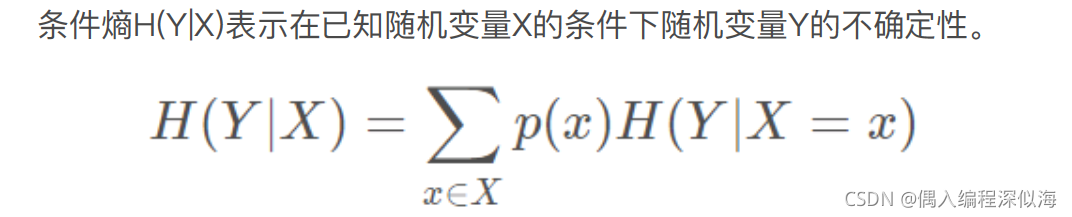
决策树及对优惠券使用进行预测案例 2021-10-01
人工智能基础总目录 决策树一、介绍决策树分类的两个步骤二、决策树的主要优点缺点三、 信息增益1 Entropy 熵3.3 Loss 函数算法流程算法优缺点四、 如何对决策树进行剪枝?预剪枝(pre-pruning)和后剪枝(post- pruning)1 预剪枝2 后剪枝五、 代码实现六、知识点总结6…

sklearn之Model selection and evaluation学习使用
这部分可以结合机器学习之模型评估与选择来阅读,sklearn库的中文地址和英文地址。 总共可以分为5部分:交叉验证来评估学习器性能;调整学习器的超参数;模型评估量化预测的质量。模型持久化。验证曲线,绘制分数来评…
sklearn学习笔记之svm
支持向量机:# -*- coding: utf-8 -*-
import sklearn
from sklearn.svm import SVC
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn import datasets
import pandas as pd
import numpydef getData_1():iris datasets.l…
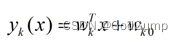
特征工程整理(仅仅是通用处理,不含个列处理)
感谢阅读1.特征工程是什么?2.数据漏斗2.1数据漏斗解决的问题2.2解决不属于同一量纲的问题归一化(区间缩放法)标准化2.3解决信息冗余的问题2.4解决缺失值问题3.特征选择3.1Filter(阈值过滤法)3.1.1 方差选择法3.1.2 相关…

sklearn中的线性回归大家族
1 概述
1.1 线性回归大家族
回归是一种应用广泛的预测建模技术,这种技术的核心在于预测的结果是连续型变量。决策树、随机森林、支持向量机的分类器等分类算法的预测标签是分类变量,多以{0,1}来表示,而无监督学习算法(如CPA、Km…
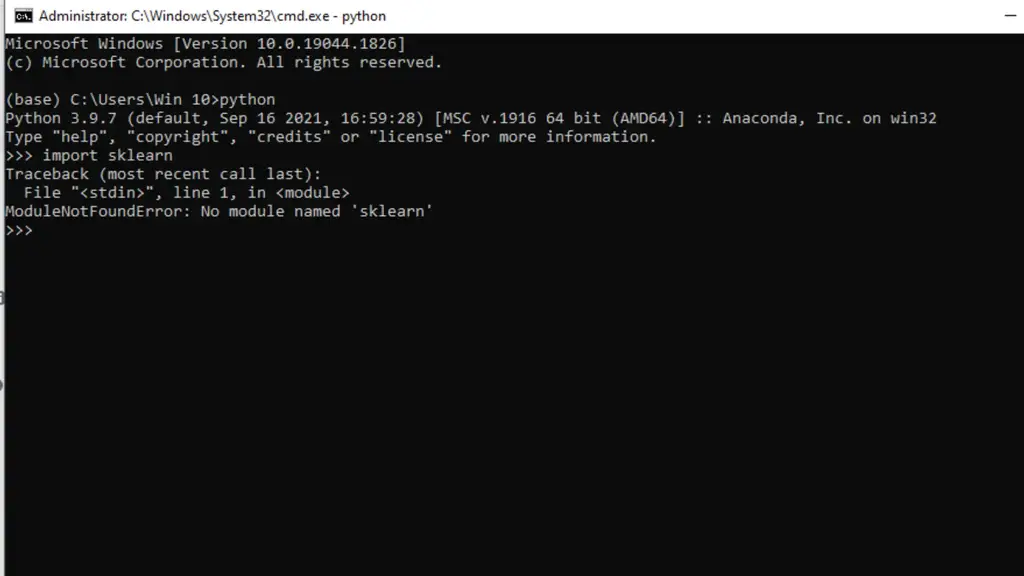
Python 中错误 ImportError: No Module Named Sklearn
在 Python 中,sklearn 被用作机器学习工具,用于在回归、集群等方面创建程序。很多时候,导入它会抛出错误—— No module named sklearn。
这意味着由于安装错误、无效的 Python 或 pip 版本或其他问题,系统无法找到它。 Python中错误ImportError: No module named sklearn…

《推荐系统实践》 第八章 评分预测问题 读书笔记
评分预测问题最基本的数据集就是用户评分数据集。该数据集由用户评分记录组成,每一条评分记录是一个三元组(u,i, r),表示用户u给物品i赋予了评分r,本章用r表示用户u对物品i的评分。因为用户不可能对所有物品都评分,因此评分预测问题就是如何通…

5328笔记 Advanced ML Chapter1-Introduction to Machine Learning Problems
5328课程大纲 PAC:概率近似正确
为何学习这门课: How machine learning works? How can we improve them? 机器学习算法中的元素:Elements of Machine Learning Algorithms
机器学习定义1:What is Machine…

人工智能基础_机器学习022_使用正则化_曼哈顿距离_欧氏距离_提高模型鲁棒性_过拟合_欠拟合_正则化提高模型泛化能力---人工智能工作笔记0062
然后我们再来看一下,过拟合和欠拟合,现在,实际上欠拟合,出现的情况已经不多了,欠拟合是
在训练集和测试集的准确率不高,学习不到位的情况.
然后现在一般碰到的是过拟合,可以看到第二个就是,完全就把红点蓝点分开了,这种情况是不好的,
因为分开是对训练数据进行分开的,如果来…
朴素贝叶斯-分类及Sklearn库实现(2)机器学习实战
上一篇文章我们简单介绍了朴素贝叶斯的前提条件以及实现过程,并介绍了几个流行的朴素贝叶斯分类法,实现了最基本的文本分类,这篇文章将继续介绍朴素贝叶斯分类,这次主要通过垃圾邮件过滤的程序实现,深化贝叶斯分类的过…

朴素贝叶斯-分类及Sklearn库实现(1)机器学习实战
KNN,决策树两种算法都明确给出了“该数据实例到底属于哪一类”这类明确的回答,而这一篇讲到的朴素贝叶斯分类器,基于概率论的分类方法,将给出数据实例属于不同种类的概率(基于数据的后验概率),从…

sklearn中数据拆分
导入包 生成数据 train_test_split拆分 kFold拆分 sKFold拆分 小结: 全部代码:
import numpy as npimport pandas as pdfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.model_selection import train_test_split# cv int 6 数据…
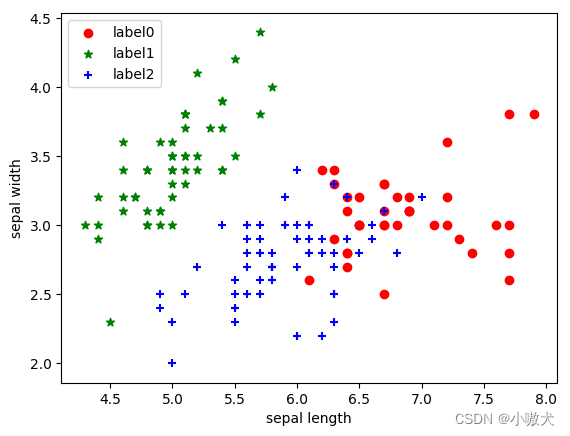
Python sklearn实现K-means鸢尾花聚类
Python sklearn实现K-means鸢尾花聚类准备1.导入相关包2.直接从sklearn.datasets中加载数据集3.绘制二维数据分布图4.实例化K-means类,并且定义训练函数5.训练6.可视化展示7.预览图准备 使用到的库: numpymatplotlibsklearn 安装: pip instal…

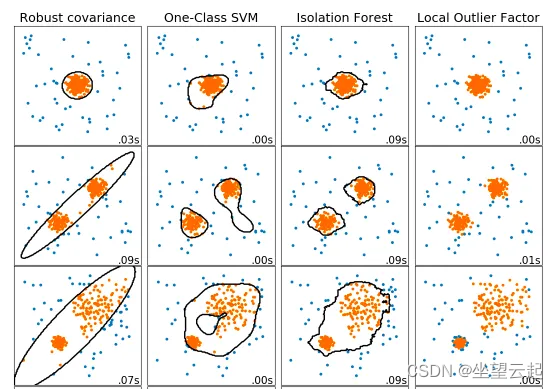
离群点检测和新颖性检测
引言
在异常检测领域中,我们常常需要决定新观测点是否属于与现有观测点相同的分布, (则称它们为inlier),或被认为是不同的(outlier). 在这里,必须做出两个重要的区别:
异常值检测:outlier detection 训练…
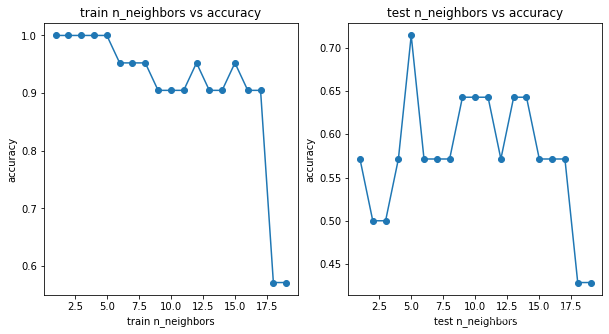
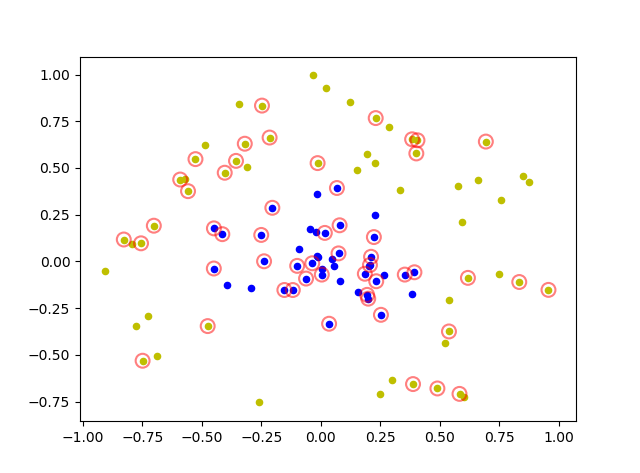
【ML】异常检测、PCA、混淆矩阵、调参综合实践(基于sklearn)
【ML】异常检测、PCA、混淆矩阵、调参综合实践(基于sklearn)加载数据可视化数据异常点检测PCA降维使用KNN进行分类并可视化计算混淆矩阵调节n_neighbors参数找到最优值加载数据
数据集:https://www.kaggle.com/datasets/yuanheqiuye/data-cl…

机器学习框架sklearn之特征提取
特征工程介绍
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
(1)什么是特征工程
特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
意义:会直接…


【Python】特征衍生
特征衍生1. 单变量特征衍生1.1 数据重编码1.2 高阶多项式2. 双变量特征衍生2.1 四则运算2.2 多项式衍生2.2.1 导包 & 数据2.2.2 二阶衍生2.2.3 三阶衍生3. 交叉组合3.1 导包 & 数据3.2 生成衍生列和名称3.3 独热编码1. 单变量特征衍生
1.1 数据重编码
连续变量 标准化…

机器学习---降维算法
降维算法:
如果拿到的数据特征过于庞大, 一方面会使得计算任务变得繁重; 另一方面, 如果数据特征还有问题, 可能会对结果造成不利的影响。 降维是机器学习领域中经常使用的数据处理方法, 一般通过某种映射…
机器学习之降维(特征选择与特征提取)
一、降维技术主要分为两大类:特征选择和特征提取。
基本概念:特征选择:我们可以选出原始特征的一个子集。特征提取:通过现有信息进行推演,构造出一个新的特征子空间。 为什么要降维: (1&a…
CART决策树以及sklearn.tree.DecisionTreeClassifier()使用
一、CART树分类
1、CART分类树的构建 利用基尼指数作为划分标准,通过样本中的特征,对样本进行划分,直到所有叶结点中的所有样本都是同一类为止,构建过程如下: (1)遍历属性和该属性可能的切…

连续属性离散化与sklearn.preprocessing.KBinsDiscretizer
1、连续属性离散化 离散化 (Discretization) (有些时候叫 量化(quantization) 或 分箱(binning)) ,是将连续特征划分为离散特征值的方法。 离散化可以把具有连续属性的数据集变换成只有名义属性(nominal attributes)的数据集。
2、K-bins 离散化(分箱&a…
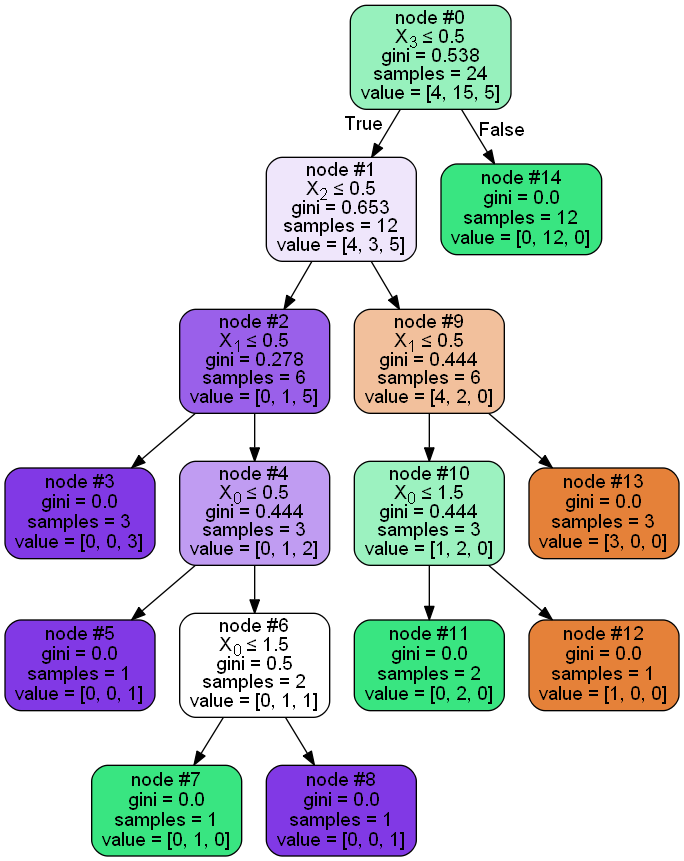
决策树-原理与Sklearn库实现(2)机器学习实战
上篇文章对决策树的基本实现过程进行了了解,关键是几种不同的特征划分方式,sklearn的特点就是代码简单,编码比较简洁,而且使用起来很方便,在基本了解决策树的实现过程后,接下来我们用时下比较流行的Sklearn…
决策树-原理与Sklearn库实现(1)机器学习实战
我们经常使用决策树处理分类问题,相比于其他分类算法,决策树算法的实现更加简单明了,而绘制出的决策树也能够轻松的看出数据隐含的内在信息,常用的决策树有CART树,ID3树,还有C4.5树,决策树的优点…
![[WinError 193] %1 不是有效的 Win32 应用程序问题解决](https://img-blog.csdnimg.cn/3462ece501de40cb89fb730db647c3c0.png)
[WinError 193] %1 不是有效的 Win32 应用程序问题解决
在cmd中执行from sklearn.datasets import load_iris竟然报错了:
Traceback (most recent call last):File "<stdin>", line 1, in <module>File "C:\Users\resus\AppData\Local\Programs\Python\Python38\lib\site-packages\sklearn\_…

kaggle泰坦尼克号数据transfrom归一化记录
首先本人是菜鸟一个,之前一直只看了些深度学习的理论知识,更多是模型方面的知识,近来在做kaggle上的入门比赛练手,发现数据预处理真的很重要,特此记录。
以下是对age和fare的归一化处理代码 为什么要进行归一详见&…

入门机器学习(西瓜书+南瓜书)决策树总结(python代码实现)
入门机器学习(西瓜书南瓜书)决策树总结(python代码实现)
一、决策树理论分析
1.1 通俗理解
决策树是一种非常经典的机器学习算法,通俗理解的话我们可以举一个例子,比如现在别人要找你借钱,那…

sklearn机器学习库(二)sklearn中的随机森林
sklearn机器学习库(二)sklearn中的随机森林
集成算法会考虑多个评估器的建模结果,汇总之后得到一个综合的结果,以此来获取比单个模型更好的回归或分类表现。
多个模型集成成为的模型叫做集成评估器(ensemble estimator)…
scikit-learn(sklearn)库中的网格搜索(Grid Search)自动化的方法来搜索最佳参数组合
前言
在机器学习中,调参是一个非常重要的步骤,它可以帮助我们找到最优的模型参数,从而提高模型的性能。然而,手动调参是一项繁琐且耗时的工作,因此,我们需要一种自动化的方法来搜索最佳参数组合。在这方面…
sklearn中主成分分析PCA参数解释
主成分分析一般用于数据降维,在应用主成分分析包scikit-learn时注意以下四点:
1、用pca.components_可以获取特征向量,且特征向量为行向量,例如W pca.components_[0, :] (或W pca.components_[0])为第一…
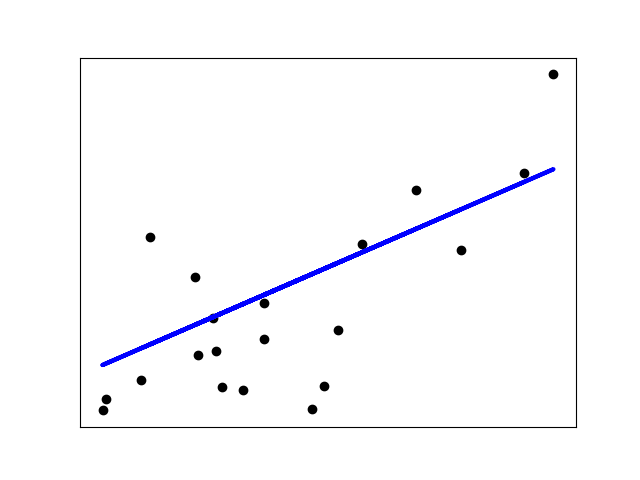
归一化的作用,sklearn 安装
目录
归一化的作用:
应用场景说明
sklearn
准备工作
sklearn 安装
sklearn 上手
线性回归实战 归一化的作用: 归一化后加快了梯度下降求最优解的速度; 归一化有可能提高精度(如KNN)
应用场景说明
1)概率模型不需要归一化ÿ…
使用 sklearn 进行数学建模的通用模板
前言
无论是本科和研究生都会有的数学建模含金量还是很高的,下面将介绍一下进行数学建模的一些基本操作方法,这里主要是利用sklearn 进行建模,包括前期的一些数据预处理以及一些常用的机器学习模型以及一些简单粗暴的通用建模步骤࿰…
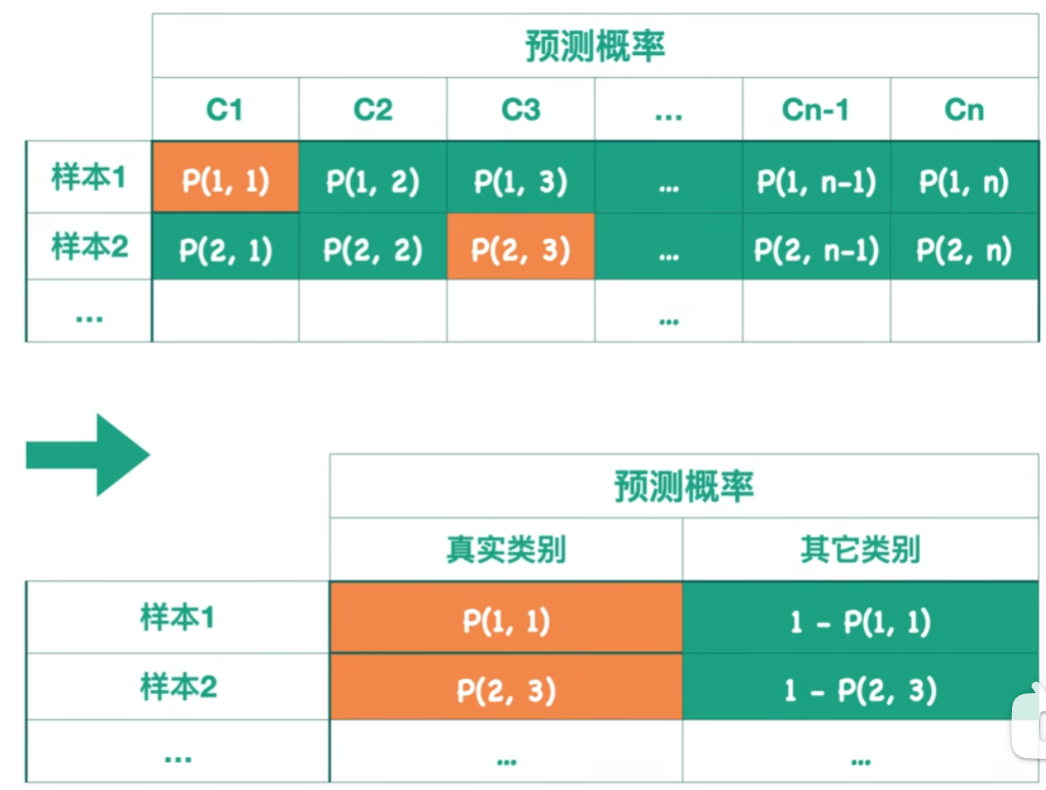
ROC曲线和AUC值
ROC曲线(Receiver Operating Characteristic,受试者工作特征)评价分类模型的可视化工具,是一条横纵坐标都限制在0-1范围内的曲线横坐标是假正率FPR,错误地判断为正例的概率纵坐标是真正率TPR,正确地判断为正…
用sklearn+opencv-python过简单的4位数字验证码
目录
生成验证码图片
用opencv-python处理图片
制作训练数据集
训练模型
识别验证码
总结与提高 在本节我们将使用sklearn和opencv-python这两个库过掉简单的4位数字验证码,验证码风格如下所示。 生成验证码图片
要识别验证码,我们就需要大量验证…
25.Pandas结合Sklearn实现泰坦尼克存活率预测
实例目标:实现泰坦尼克存活预测
处理步骤: 1、输入数据:使用Pandas读取训练数据(历史数据,特点是已经知道了这个人最后有没有活下来) 2、训练模型:使用Sklearn训练模型 3、使用模型:对于一个新的不知道存活…
K近邻算法(K-Nearest Neighbors, KNN)原理详解与应用
目录 1. KNN算法概述2. 距离度量3. K值选择4. 分类任务5. 回归任务6. KNN的优缺点7. KNN算法应用 K近邻算法(K-Nearest Neighbors, KNN)是一种常用的非参数化的监督学习算法,用于分类和回归任务。本文将深入解析KNN的原理,从距离度…
【Python机器学习】sklearn.datasets回归任务数据集
为什么回归分析在数据科学中如此重要,而sklearn.datasets如何助力这一过程?
回归分析是数据科学中不可或缺的一部分,用于预测或解释数值型目标变量(因变量)和一个或多个预测变量(自变量)之间的关系。sklearn.datasets模块提供了多种用于回归分析的数据集,这些数据集常…
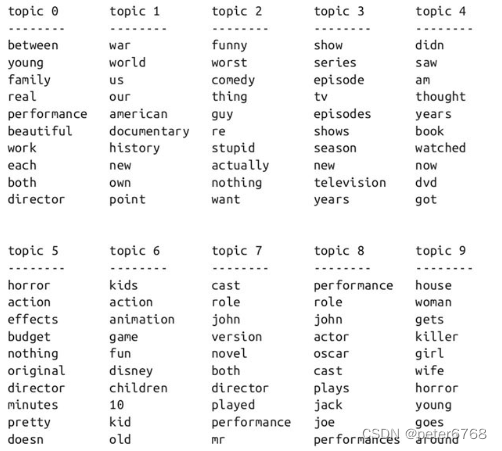
sknearl-7处理文本数据
本章代码大部分没跑,只供学习
第四节特征工程里提到,有连续特征和离散特征,对于文本数据,文本特征可以看作第三种特征
1 用字符串表示的数据类型
2 例子 电影评论情感分析
给定一个影评(输入)ÿ…

sklearn笔记:neighbors.NearestNeighbors
1 最近邻
class sklearn.neighbors.NearestNeighbors(*, n_neighbors5, radius1.0, algorithmauto, leaf_size30, metricminkowski, p2, metric_paramsNone, n_jobsNone)邻居搜索算法的选择通过关键字 algorithm 控制,它必须是 [auto, ball_tree, kd_tree, brute] …
机器学习/sklearn笔记:MeanShift
1 算法介绍
一种基于质心的算法通过更新候选质心使其成为给定区域内点的均值候选质心的位置是通过一种称为“爬山”技术迭代调整的,该技术找到估计的概率密度的局部最大值
1.1 基本形式
给定d维空间的n个数据点集X,那么对于空间中的任意点x的均值漂移…

猫头虎分享已解决Error: 成功解决“No module named ‘sklearn‘ (ModuleNotFoundError)“
博主猫头虎的技术世界 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能! 文章目录 猫头虎分享已解决Error: 成功解决"No module named sklearn (ModuleNotFoundError)" 🐱🦉🔧摘要正文内容 介绍错误原因分析…

Python关于numpy,pandas,sklearn,tensorflow,kreas相关问题
大纲最重要的问题(理解的前提条件)1.到底python是个啥?第三方库的通俗介绍2.Anaconda到底是个啥?装的好处不装的坏处Python pip 安装语句 与 Anaconda装包语句包的安装注意事项清华、中科院镜像是什么?最重要的问题&am…
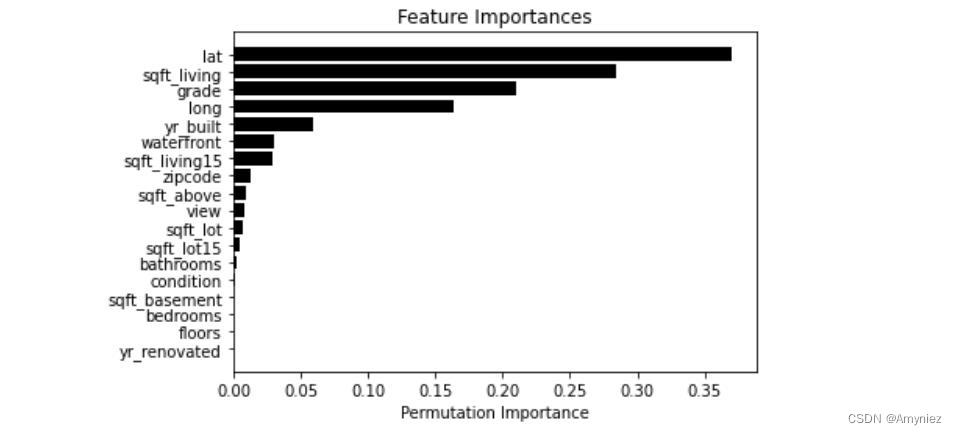
机器学习笔记 十八:基于3种方法的随机森林模型分析房屋参数重要性
这里写自定义目录标题1. 探索性数据分析1.1 数据集分割(训练集、测试集)1.2 模型拟合2. 特征重要性比较2.1 Gini Importance2.2 Permutation Importance2.3 Boruta3. 特征比较3.1 Gini Importance3.2 Permutation Importance3.3 Boruta4. 模型比较将机器…
GBDT之GradientBoostingRegressor参数详解以及调参
GBDT之GradientBoostingRegressor参数详解以及调参 一、参数、属性及方法1、参数(1)loss(2)learning_rate(3)n_estimators(4)subsample(5)criterion(6)min_samples_split(7)min_samples_leaf(8)min_weight_fraction_leaf(9)max_depth(10)min_impurity_decr…
【机器学习】sklearn特征选择(feature selection)
文章目录 特征工程过滤法(Filter)方差过滤相关性过滤卡方过滤F验表互信息法小结 嵌入法(Embedded)包装法(Wrapper) 特征工程
特征提取(feature extraction)特征创造(feature creation)特征选择(feature se…
Sklearn支持向量机
支持向量机(Support Vector Machine, SVM)是一种常用的分类算法,它可以用于解决二分类和多分类问题。在Python中,你可以使用Sklearn库来实现SVM。下面是一个简单的例子,展示了如何使用Sklearn进行SVM分类。
# 导入必要…
创建旅游景点图数据库Neo4J技术验证
文章目录 创建旅游景点图数据库Neo4J技术验证写在前面基础数据建库python3源代码KG效果KG入库效率优化方案PostGreSQL建库 创建旅游景点图数据库Neo4J技术验证
写在前面
本章主要实践内容: (1)neo4j知识图谱库建库。使用导航poi中的公园、景…
Sklearn K-均值算法
以下是一个使用Sklearn库实现K-均值聚类算法的简单代码示例。K-均值算法是一种迭代算法,用于将数据集分为K个簇,使得每个簇的内部平方误差最小。
# 导入必要的库
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
imp…
导入fetch_california_housing 加州房价数据集报错解决(HTTPError: HTTP Error 403: Forbidden)
报错
HTTPError Traceback (most recent call last)
Cell In[3], line 52 from sklearn.datasets import fetch_california_housing3 from sklearn.model_selection import train_test_split
----> 5 X, Y fetch_california_housing(retu…
Python 训练集、测试集以及验证集切分方法:sklearn及手动切分
目录
方法一
方法二 需求目的:针对模型训练输入,按照6:2:2的比例进行训练集、测试集和验证集的划分。当前数据量约10万条。如果针对的是记录条数达上百万的数据集,可按照98:1:1的比例进行切分。
方法一:切分训练集和测试集&…

【分类评估指标,精确率,召回率,】from sklearn.metrics import classification_report
from: https://zhuanlan.zhihu.com/p/368196647
多分类
from sklearn.metrics import classification_report
y_true [0, 1, 2, 2, 2]
y_pred [0, 0, 2, 2, 1]
target_names [class 0, class 1, class 2]
# print(classification_report(y_true, y_pred, targe…

sklearn中一些简单机器学习算法的使用
目录 前言
KNN算法
决策树算法
朴素贝叶斯算法
岭回归算法
线性优化算法 前言
本篇文章会介绍一些sklearn库中简单的机器学习算法如何使用,一些注释已经写在代码中,帮助一些小伙伴入门sklearn库的使用。
注意:本篇文章只涉及到如何使用…
成功解决No module named ‘sklearn‘(ModuleNotFoundError)
成功解决No module named ‘sklearn’(ModuleNotFoundError) 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程 👈 希望得到您…
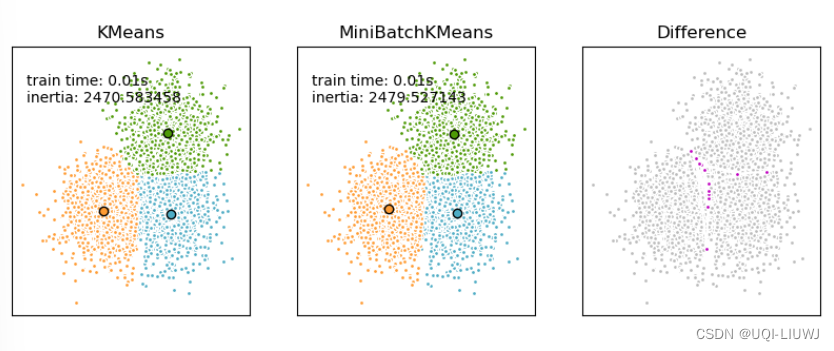
机器学习/sklearn 笔记:K-means,kmeans++,MiniBatchKMeans
1 K-means介绍
1.0 方法介绍
KMeans算法通过尝试将样本分成n个方差相等的组来聚类,该算法要求指定群集的数量。它适用于大量样本,并已在许多不同领域的广泛应用领域中使用。KMeans算法将一组样本分成不相交的簇,每个簇由簇中样本的平均值描…
sklearn 笔记:聚类
1 sklearn各方法比较 方法名称参数使用场景K-means簇的数量 非常大的样本数 中等簇数 簇大小需要均匀 Affinity Propagation 阻尼系数 样本偏好 样本数不能多 簇大小不均 MeanShift带宽 样本数不能多 簇大小均匀 谱聚类簇的数量 中等样本数 小簇数 簇大小均匀 层次聚类簇的数量…
如何基于gensim和Sklearn实现文本矢量化
大家利用机器学习或深度学习开展文本分类或关联性分析之前,由于计算机只能分析数值型数据,而人类所熟悉的自然语言文字,机器学习算法是一窍不通的,因此需要将大类的文本及前后关系进行设计,并将其转换为数值化表示。一…

sklearn随机森林 测试 路面点云分类
一、特征5个坐标 坐标-特征-类别 训练数据 二、模型训练
记录分享给有需要的人,代码质量勿喷
import numpy as np
import pandas as pd
import joblib#region 1 读取数据
dir D:\\py\\RandomForest\\
filename1 trainRS
filename2 .csv
path dirfilename1file…
sklearn所需要的知识点
NumPy
NumPy(Numerical Python的简称)是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵&am…
【小沐学NLP】Python实现TF-IDF算法(nltk、sklearn、jieba)
文章目录 1、简介1.1 TF1.2 IDF1.3 TF-IDF2.1 TF-IDF(sklearn)2.2 TF-IDF(nltk)2.3 TF-IDF(Jieba)2.4 TF-IDF(python) 结语 1、简介
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF是词频(Term Fr…
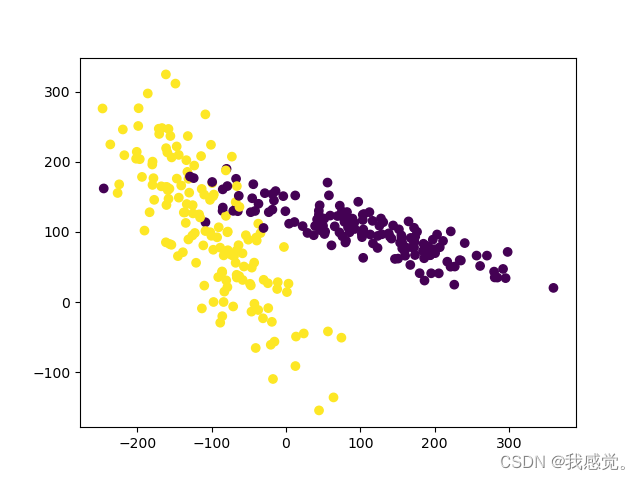
【sklearn练习】preprocessing的使用
介绍
scikit-learn 中的 preprocessing 模块提供了多种数据预处理工具,用于准备和转换数据以供机器学习模型使用。这些工具可以帮助您处理数据中的缺失值、标准化特征、编码分类变量、降维等。以下是一些常见的 preprocessing 模块中的功能和用法示例: …
使用Scikit Learn 进行识别手写数字
使用Scikit Learn 进行识别手写数字 作者:i阿极 作者简介:数据分析领域优质创作者、多项比赛获奖者:博主个人首页 😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏…
探索sklearn中SVM模型的原理及使用案例
大家好,支持向量机(Support Vector Machines,SVM)是一种经典的机器学习算法,被广泛应用于分类和回归任务中。在sklearn库中,SVM模型提供了简单易用的API,使得开发者可以方便地应用SVM算法解决实…
K-Means 与 DBSCAN 算法
K-Means 与 DBSCAN 算法 K-Means 算法概述K-Means 算法原理算法步骤 K-Means 算法调用示例 DBSCAN 算法概述DBSCAN 算法原理DBSCAN 算法调用示例 其他机器学习算法:机器学习实战工具安装和使用 K-Means 和 DBSCAN 算法是常用的无监督学习算法,用于数据聚…

机器学习第三课(sklearn接口)
一、sklearn基本知识
中文官网 英文官网 注意:sklearn第三方模块的安装 要用pip install scikit-learn from sklearn.neighbors import KNeighborsClassifier
# 1 准备数据
# 训练集的特征数据 2维
x [[-2],[-1],[2],[3],[4]]
# 训练集的目标数据 1维
y [0,0,1,…
python环境安装sklearn及报错解决
安装
如刚开始安装,还未遇到问题请直接从重新安装库开始看,如果遇到报错,从问题开始看
问题
python安装sklearn报错 ,报错信息如下
File "<stdin>", line 1pip install scikit-learn^
SyntaxError: invalid s…
sklearn.cluster.Kmeans解析
sklearn.cluster.KMeans(n_clusters8,initk-means,n_init10, max_iter300, tol0.0001, precompute_distancesauto,verbose0, random_stateNone, copy_xTrue,n_jobs1,algorithmauto) n_clusters: 生成类别数, int, optional, default: 8. init: 初始化方法, 默认为‘…
Python-sklearn-LinearRegression
目录
1 手动实现/使用sklearn实现线性回归训练
1.1 单特征线性回归(One Feature)
1.2 多特征线性回归(Multiple Features)
1.3 多项式线性回归(Polynomial) 1 手动实现/使用sklearn实现线性回归训练
1…
极简sklearn上手教程,快速体验特性
文章目录 极简sklearn上手教程,快速体验特性1. **环境搭建与安装**2. **用户指南:监督学习模块 - 线性模型**3. **模型评估与选择 - 超参数调优**4. **数据预处理与转换 - 标准化**5. **统计检验与依赖分析 - 部分依赖图**6. **大规模计算与性能优化 - 并…

from sklearn.preprocessing import LabelEncoder的详细用法
sklearn.preprocessing 0. 基本解释1. 用法说明2. python例子说明 0. 基本解释
LabelEncoder 是 sklearn.preprocessing 模块中的一个工具,用于将分类特征的标签转换为整数。这在许多机器学习算法中是必要的,因为它们通常不能处理类别数据。
1. 用法说…
朴素贝叶斯基本原理sklearn实现
理论
先验概率:根据以往的分析经验得到的概率,先验概率不需要样本数据 后验概率:根据数据的特征进行分析 联合概率:几个事件同时发生的概率,P(瓜熟,瓜蒂脱落) 定义 贝叶斯分类是一类分类算法的…

python一元线性回归sklearn
# -*- coding: utf-8 -*-from sklearn.linear_model import LinearRegression
import numpy as np
import matplotlib.pyplot as plt# 载入数据
data np.genfromtxt(一元线性回归.csv, delimiter,)
x_data data[:,0]
y_data data[:,1]
plt.scatter(x_data,y_data)
plt.show(…
python sklearn labelencoder、OneHotEncoder和get_dummies的区别
文章目录 labelencoderOneHotEncoderget_dummiesLabelBinarizer labelencoder
LabelEncoder 将不连续的数字or文本进行编号
import numpy as np
import pandas as pd
data pd.DataFrame({"学号":[1001,1002,1003,1004],"性别":["男","女…
临近取样(KNN)算法基本原理sklearn实现
1 KNN定义
KNN可以说是最简单的分类算法之一,同时,它也是最常用的分类算法之一,KNN算法是有监督学习中的分类算法,它看起来和Kmeans有点像(Kmeans是无监督学习算法),但却是有本质区别的。
KNN…

【Pytorch】新手入门:基于sklearn实现鸢尾花数据集的加载
【Pytorch】新手入门:基于sklearn实现鸢尾花数据集的加载 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程👈 希望…
Sklearn交叉验证
scikit-learn提供了多种交叉验证的方法,主要包括以下几种类型:
K折交叉验证(K-Fold Cross Validation): 这种方法将数据集分成K个大小相等的互斥子集。每次选择一个子集作为验证集,剩余的K-1个子集作为训练集。这个过…
sklearn实现数据标准化(Standardization)和归一化(Normalization)
标准化(Standardization)
sklearn的标准化过程,即包括Z-Score标准化,也包括0-1标准化,并且即可以通过实用函数来进行标准化处理,同时也可以利用评估器来执行标准化过程。接下来我们分不同功能以的不同实现…
K 近邻算法解析: 从原理到实践的机器学习指南
机器学习 第三课 k 近邻 概述机器学习简介K 近邻算法K 近邻中的距离欧氏距离曼哈顿距离余弦相似度 选择合适的 K 值奇数 vs 偶数通过交叉验证选择 k 值 实战分类问题回归问题 K 近邻算法的优缺点优点缺点 手把手实现 k 近邻手搓算法实战分类 概述
机器学习 (Machine Learning)…
Sklearn基本算法
sklearn(Scikit-learn)是一个非常流行的Python机器学习库,它提供了一系列简单高效的算法和工具,适用于各种机器学习任务。下面是一些基本的机器学习算法类别和对应的常用算法:
分类算法
逻辑回归(Logisti…
如何基于OpenCV和Sklearn算法库开展机器学习算法研究
大家在做机器学习或深度学习研究过程中,不可避免都会涉及到对各种算法的研究使用,目前比较有名的机器学习算法库主要有OpenCV和Scikit-learn(简称Sklearn),二者都支持各种机器学习算法,主要有监督学习、无监…

知识图谱:py2neo将csv文件导入neo4j
文章目录 安装py2neo创建节点-连线关系图导入csv文件删除重复节点并连接边 安装py2neo
安装python中的neo4j操作库:pip install py2neo 安装py2neo后我们可以使用其中的函数对neo4j进行操作。
图数据库Neo4j中最重要的就是结点和边(关系)&a…
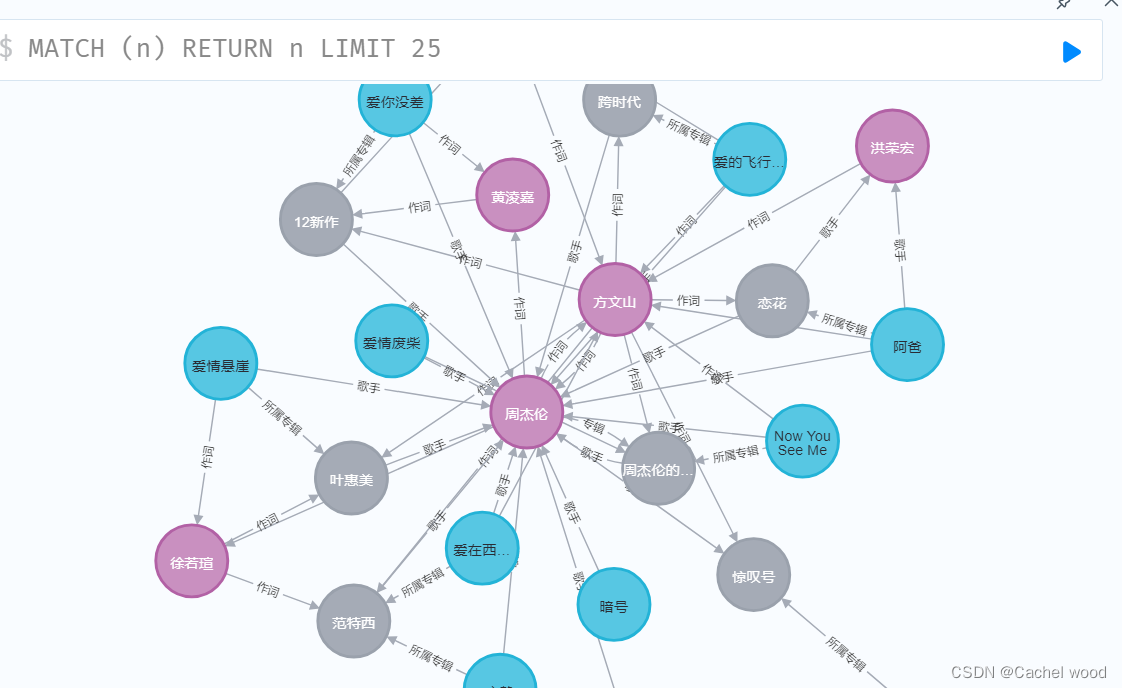
Py2neo查询neo4j周杰伦数据库中的节点、关系和路径教程
文章目录 py2neo介绍连接Neo4j数据库py2neo查询图数据库neo4j数据概览使用NodeMatcher查询节点使用RelationshipMatcher查询关系 通过执行Cypher语句查询 py2neo介绍
Neo4j是一款开源图数据库,Py2neo提供了使用Python语言访问Neo4j的接口。本文介绍了使用Py2neo的N…
Python中常用的库-sklearn的介绍和代码案例
Python中常用的库-sklearn的介绍和代码案例
关注B站查看更多手把手教学: 肆十二-的个人空间-肆十二-个人主页-哔哩哔哩视频 (bilibili.com) 今天我们来一起说下最近python中常用的机器学习库-sklearn。
Scikit-learn是一个基于Python的开源机器学习库,…
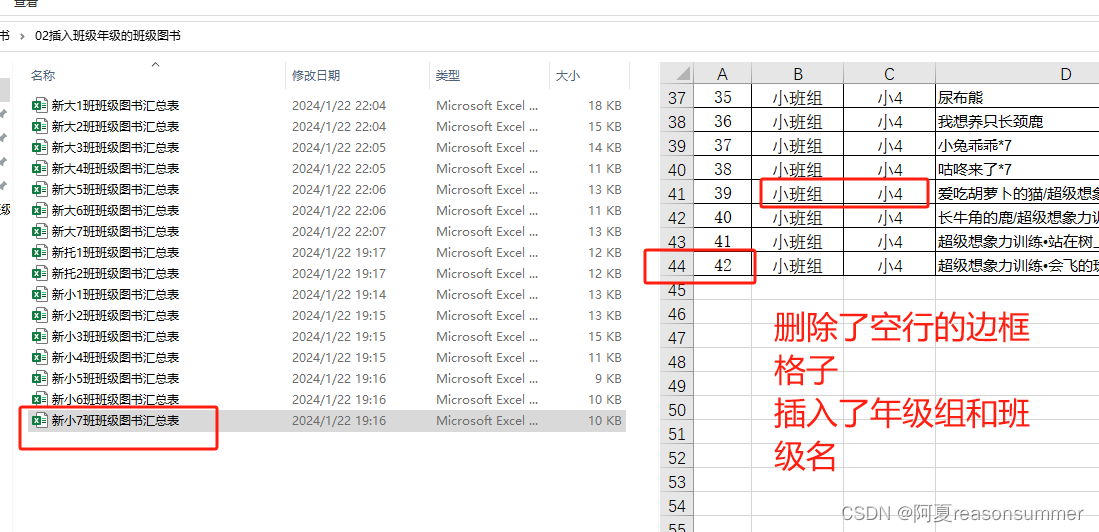
【办公类-19-02】20240122图书EXCEL插入列并删除空行
作品展示 背景需求
上次23个班级班主任统计图书,写在EXCEL内
【办公类-19-01】20240108图书统计登记表制作(23个班级)EXCEL复制表格并合并表格-CSDN博客文章浏览阅读693次,点赞12次,收藏7次。【办公类-19-01】202401…
简单线性回归原理sklearn简单实现
1. 回归与分类
回归模型:针对于连续值的预测,即线性关系
分类模型:预测离散值,非线性,针对于分类问题2. 回归
回归算法是相对分类算法而言的,与我们想要预测的目标变量y的值类型有关。
如果目标变量y是分…

Python图像处理【20】图像金字塔
图像金字塔 0. 前言1. 高斯金字塔与拉普拉斯金字塔2. 计算图像金字塔2.1 构建高斯金字塔2.2 构建拉普拉斯金字塔2.3 根据拉普拉斯金字塔重建图像 3. 利用金字塔混合图像小结系列链接 0. 前言
将一组具有不同分辨率的图像(所有图像都从给定的输入图像中获得)保存在堆栈中&#…

详解机器学习概念、算法
目录 前言 一、常见的机器学习算法 二、监督学习和非监督学习 三、常见的机器学习概念解释 四、深度学习与机器学习的区别 基于Python 和 TensorFlow 深度学习框架实现简单的多层感知机(MLP)神经网络的示例代码: 欢迎三连哦! 前言…
sklearn.svm.SVC 支持向量机-简介
sklearn.svm.SVC 是 Scikit-learn(一个常用的机器学习库)中的一个类,用于支持向量机(Support Vector Machine,SVM)算法中的分类任务。
SVM 是一种用于分类和回归的监督学习算法。在分类任务中,…